Algoritmy a datové struktury 2
Při sepisování poznámek jsem hodně čerpala z Průvodce labyrintem algoritmů. Z knihy jsem přejala většinu značení a mnoho obrázků.
Prohledávání řetězců
- hledání podřetězců v řetězcích – „hledání jehly v kupce sena”
Značení
– jehla
– seno
Σ – abeceda
– slova/řetězce
– znaky
– délka řetězce
– prázdný řetězec
– zřetězení řetězců a
– i-tý znak řetězce
– podřetězec řetězce
- vynechání dolní meze – prefix
- vynechání horní meze – sufix
Inkrementální algoritmus
- začínáme od prázdného řetězce a na konec přidáváme postupně znaky sena
- Jaký je nejdelší prefix jehly, který je sufixem sena?
Knuth-Morris-Pratt algoritmus
- vyhledávací automat
- vrcholy – prefixy jehly
- dopředné hrany – přidání písmenka
- zpětné hrany – kam se přesunout, když vyhledávání failne
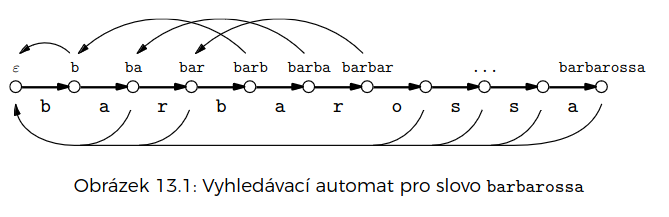
v paměti můžeme reprezentovat buďto jako graf, nebo jako pole na zpětné hrany (na dopředné stačí samotná jehla)
procházíme seno a chodíme jehlou po hranách podle znaků, na které narážíme
pokud se dostaneme do koncového stavu, ohlásíme výskyt jehly a vrátíme se na začátek

- Stav sena je roven maximální délce prefixu jehly, která je sufixem zatím zpracovaného sena
Analýza složitosti
Lemma: Funkce běží v čase
- projdeme po nejvýše dopředných hranách (to ale neplatí pro zpětné hrany)
- každá dopředná hrana vede o právě 1 stav doprava a každá zpětná alespoň o 1 stav doleva
- průchodů po zpětných hranách je nejvýše tolik, kolik dopředných – nejvýše
Konstrukce automatu
- budeme stavět automat pomocí sama sebe (wha-…?)
- pořídíme si automat jen s dopřednými hranami a doplníme zpětnou hranu ze stavu 1 do stavu 0
- následně budeme doplňovat zpětné hrany pro další stavy
- pro stav můžeme v pohodě používat tento automat pro jehly délky
- předhodíme tedy automatu ten samý stav bez prvního písmenka a tam kde skončíme, tam bude vést zpětná hrana ze stavu
- nejlíp jde tohle pochopit, když si to člověk sám vyzkouší
Analýza složitosti
- spouštění automatu postupně na řetězce by nás stálo
- každý z těchto řetězců je prefixem toho následujícího – stačí spustit na a zaznamenávat postup
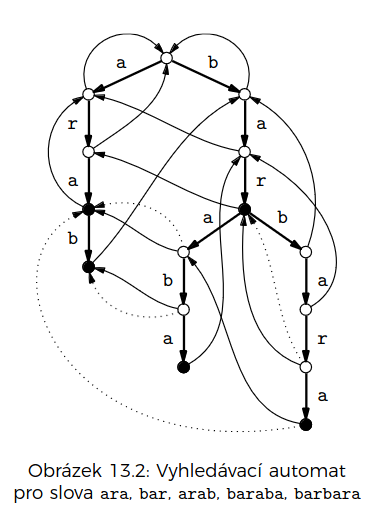
Aho-Corasicková
– seno
– jehly
– počet výskytů jehel v seně
Automat
stavy = prefixy jehel
dopředné hrany:
konce jehel
sestavíme si trii
na ní postavíme stejné zpětné hrany jako na KMP
- problém: co když bychom v senu došli do bodu, kde končí výskyty dvou různých jehel?
- řešení: vytvoříme si zkratové hrany do terminálních vrcholů
- Zkratková hrana ze stavu vede do nejbližšího koncového stavu dosažitelného z po zpětných hranách (a různého od )
Reprezentace
- pro každý očíslovaný stav (0 = kořen, pak libovolně) automatu si pamatujeme:
- číslo stavu, kam vede zpětná hrana
- číslo stavu, kam vede zkratková hrana
- zda tu končí nějaké slovo a pokud ano, které
- kam vede dopředná hrana označená písmenem
Algoritmus


Analýza složitosti
- počet dopředných hran, které projdu je nejvýše
- počet zpětných hran, které projdu je nejvýše počet projitých hran dopředných (stejný argument jako u KMP)
Konstrukce automatu
- zpětné hrany vedou napříč mezi různými jehlami
- musíme budovat po hladinách (BFS)
- opět začneme jen s triviálními zpětnými hranami do nulového stavu
- v každé iteraci algoritmu rozšíříme každou jehlu o jednu vrstvu následujících znaků

- konstrukce zpětných hran hledá všechny jehly, jen kroky jednotlivých hledání vhodně střídá
- časová složitost je tedy shora omezena součtem složitostí hledání jehel –
- počet projití po zkratkových hranách je roven počtu výskytů –
Rabin–Karp
- pro hledání jedné jehly délky v seně délky
- budeme posouvat okénko délky po seně a pro každý podřetězec si počítat hash
- pokud se hash podřetězce rovná hashi jehly, zkontroluji lineárně, jestli je nalezený řetězec opravdu stejný jako jehla
- problém: hashování je lineární
Hashovací funkce
- chceme hashovací funkci, která je schopna se přepočítat při posunutí okénka o jedno doprava v konstantním čase
písmena jsou přirozená čísla
je nějaká vhodná konstanta
- musí být nesoudělná s !!!
- musí být řádově větší než
budeme chtít volit (odůvodnění později)
při posunutí okénka o jedno doprava:

Analýza složitosti
pokud si mocniny předpočítáme, proběhne aktualizace v
- inicializace v
v každé poloze okénka můžeme strávit až času
- složitost – au au
řetězce porovnáváme když:
- nastane výskyt
- hash jehly se shoduje s hashem okénka (ač se řetězce nerovnají)
- pravděpodobnost (za předpokladu dokonale náhodného chování hashovací funkce)
v průměru tedy spotřebujeme čas
- inicializace + průchod senem + kontrola pravých výskytů + kontrola falešných výskytů
pokud nám bude stačit najít jen první výskyt a , časová složitost bude v průměru
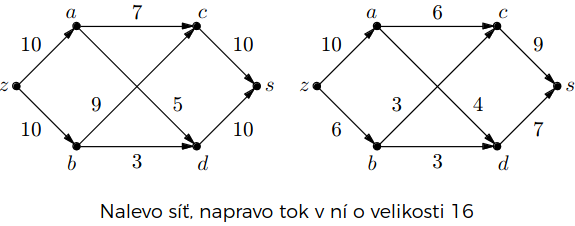
Toky v sítích
- intuitivní představa:
- síť trubek popsaná orientovaným grafem
- hrany ohodnocené „kapacitami” – kolik tekutiny jimi může protéct za jednotku času
- dva význačné vrcholy – zdroj a stok
- síť trubek popsaná orientovaným grafem
Síť
Definice: Síť je uspořádaná pětice , kde:
je orientovaný graf
je funkce přiřazující hranám jejich kapacity
jsou dva různé vrcholy grafu, kterým říkáme zdroj a stok
o grafu budeme předpokládat, že je búno symetrický
- pro hrany bez si jednoduše přidáme hranu s nulovou kapacitou
Tok
Definice: Tok v síti je funkce , pro níž platí:
Tok po každé hraně je omezen její kapacitou .
Kirchhoffův zákon: Do každého vrcholu přiteče stejně, jako z něj odteče („síť těsní”).
Výjimku může tvořit pouze zdroj a spotřebič. Formálně:
celkový přítok do vrcholu:
celkový odtok z vrcholu:
přebytek ve vrcholu:
Kirchhoffův zákon:
Lemma:
mějme součet přebytků všech vrcholů
dle Kirchhoffova zákona může být přebytek nenulový pouze ve zdroji a spotřebiči
zároveň je to součet kladných a záporných toků po hranách, přičemž každá přispěje jednou kladně (ve vrcholu, do kterého vede) a jednou záporně (ve vrcholu, odkud vede)
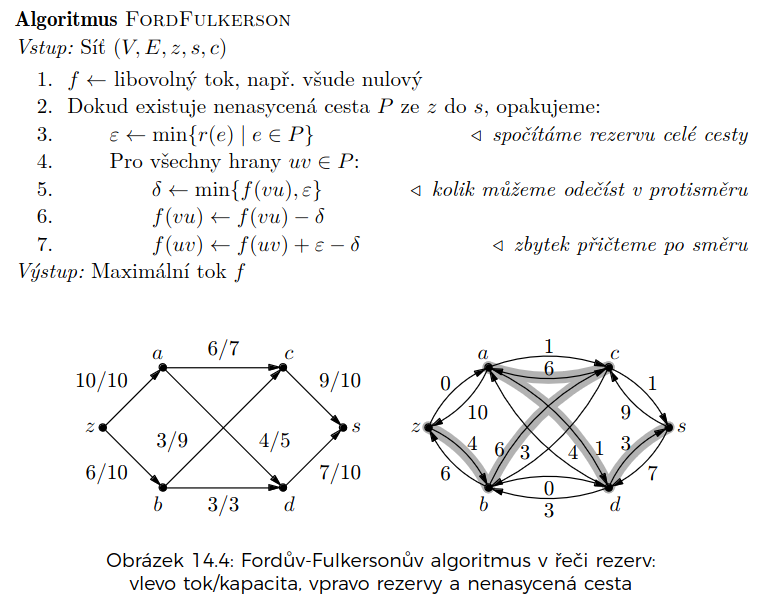
Ford-Fulkerson
začneme s nulovým tokem a postupně ho budeme vylepšovat
rezerva hrany :
- kolik můžeme ještě poslat tekutiny po směru a protisměru
nasycená hrana: hrana s nulovou rezervou
nenasycená hrana: hrana s kladnou rezervou
nasycená cesta: cesta s alespoň jednou nasycenou hranou
- touhle cestou už nemůžeme poslat více tekutiny (porušili bychom tak Kirchhoffův zákon)
nenasycená cesta: cesta se všemi hrany nenasycenými
Konečnost
algoritmus zachovává celočíselnost
velikost toku se v každém kroku zvýší alespoň o 1
- algoritmus se zastaví po nejvýše tolika krocích, kolik je horní mez pro velikost maximálního toku
pro racionální kapacity stačí vynásobit velikosti všech hran nejmenším společným násobkem jejich jmenovatelů
pro iracionální kapacity se nemusí algoritmus nikdy zastavit, ba ani konvergovat ke správnému výsledku
Analýza složitosti
pro síť, jejíž jednotky jsou racionální a jejíž maximální tok je , nalezne Ford-Fulkersonův algoritmus maximální tok v čase ( je počet hran)
- nenasycenou cestu najdeme a zlepšíme v čase prohledáním grafu
- každé prohledání zlepší tok alespoň o 1, počet iterací je omezen velikostí maximálního toku
pokud budeme v FF používat BFS, bude časová složitost
- této úpravě se říká algoritmus Edmonds-Karp, na jehož myšlence pak vznikl Dinicův algoritmus
- hezké počtení o něm je zde
Maximalita toku
- pro důkaz využijeme řezy
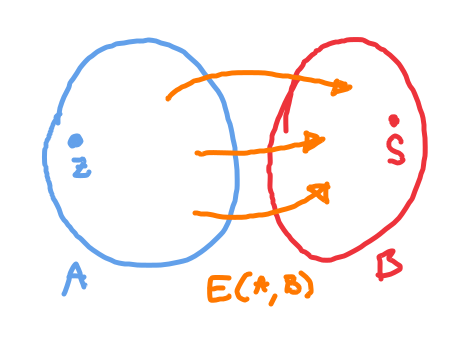
a : množiny vrcholů, které dohromady obsahují všechny vrcholy sítě a jsou zároveň disjunktní
- v musí ležet zdroj a v stok
: množina hran vedoucích z do (elementární řez)
– tok z do
- počítám pouze hrany orientované z do
– čistý tok z do
- počítám i zpetný tok z do
Pro každý řez a každý tok platí
- opět se odkazuji na Kirchhoffův zákon – co vyteče ze , musí někam dotéct
- pro důkaz stačí sečíst přebytky ve vrcholech
- díky tomuto pozorování můžeme měřit celkovou velikost toku na jakémkoliv řezu
Lemma: pokud se Ford-Fulkersonův algoritmus zastaví, vydá maximální tok
- nechť se algoritmus zastaví
- mějme množiny vrcholů
- množina je řez
- zdroj je v – ze do existuje nenasycená cesta délky 0
- stok je v – kdyby nebyl, existovala by nenasycená cesta ze do a algoritmus by tedy ještě neskončil (spor)
- všechny hrany řezu mají nulovou rezervu
- po všech hranách řezu vedoucích z do teče tok rovný kapacitě hran a po hranách z do neteče nic
- je minimální je maximální
- po všech hranách řezu vedoucích z do teče tok rovný kapacitě hran a po hranách z do neteče nic
Maximální párování
párování – množina hran taková, že žádné dvě hrany nemají společný vrchol
mějme bipartitní graf a přetvořme ho na síť takto:
- rozdělíme graf na levou a pravou partitu
- všechny hrany zorientujeme zleva doprava
- přidáme zdroj a vedeme z něj hrany do všech vrcholů levé partity
- přidáme stok a vedeme do něj hrany ze všech vrcholů pravé partity
- všem hranám nastavíme jednotkovou kapacitu
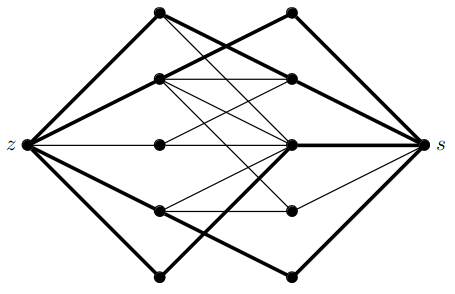
v této síti pak najdeme největší celočíselný tok pomocí Ford-Fulkersonova algoritmu
nalezené párování je největší možné
- z toku vytvoříme párování o tolika hranách, kolik je velikost toku a naopak z každého párování umíme vytvořit celočíselný tok odpovídající velikosti
- bijekce mezi množinou všech celočíselných toků a množinou všech párování, která zachovává velikost
- z toku vytvoříme párování o tolika hranách, kolik je velikost toku a naopak z každého párování umíme vytvořit celočíselný tok odpovídající velikosti
Analýza složitosti
- pro síť, jejíž kapacity jsou jednotkové, nalezne Ford-Fulkersonův algoritmus maximální tok v čase ( je počet vrcholů, počet hran)
- nenasycenou cestu najdeme a zlepšíme v čase prohledáním grafu
- každé prohledání zlepší tok alespoň o 1, počet iterací je omezen velikostí maximálního toku, což je pro síť hran s jednotkovými kapacitami hran nejvýše
Dinicův algoritmus
- zlepšuje tok pomocí jiného toku
Síť rezerv
- kapacita každé hrany je nahrazena rezervou při toku
Definice: každé hraně přiřadíme její průtok (tok tam mínus tok zpět)
- – plyne z předchozích dvou
- pro všechny vrcholy platí, že
- opět Kirchhoffův zákon – co přiteče hranami dovnitř, vyteče hranami na druhé straně ven
- stejný vztah jako pro přebytek popsaný ve FF alg.
Lemma P (o průtoku)
pokud funkce splňuje podmínky , , a , pak existuje tok , jehož průtokem je .
tok určíme pro každou dvojici hran a zvlášť
předpokládejme, že
- pak a
- díky funkce nepřekračuje kapacity a díky pro ni platí Kirchhoffův zákon
- je to tok
Lemma Z (o zlepšování toků)
pro každý tok v síti a libovolný tok v síti rezerv lze v čase nalézt tok v síti takový, že .
- nemůžeme sčítat přímo toky, ale můžeme sčítat průtoky po jednotlivých hranách
podmínka platí pro i , tudíž platí i pro jejich součet
víme, že , tudíž
stejný důkaz jako pro
když se sečtou průtoky, sečtou se i přebytky
- nemůžeme sčítat přímo toky, ale můžeme sčítat průtoky po jednotlivých hranách
Definice: Tok je blokující, jestliže na každé orientované cestě ze zdroje do spotřebiče existuje alespoň jedna hrana, na níž je tok roven kapacitě
- v řeči FF – všechny cesty jsou nasycené
Definice: Síť je vrstevnatá (pročištěná), pokud každý vrchol i hrana leží na nějaké nejkratší cestě ze do
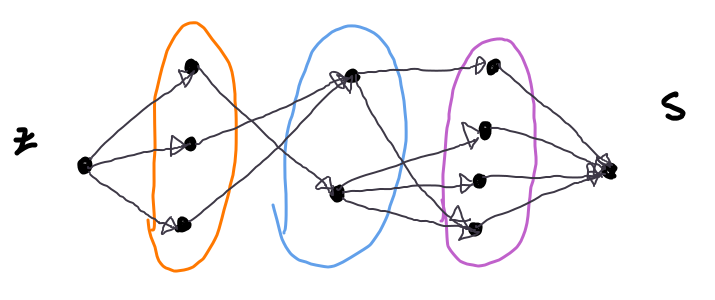

- je maximální tok, protože na konci neexistuje cesta s kladnou rezervou, což odpovídá momentu, kdy se zastaví FF algoritmus, který pokud se zastaví, určitě vydá maximální tok (což už jsme si dokázali)
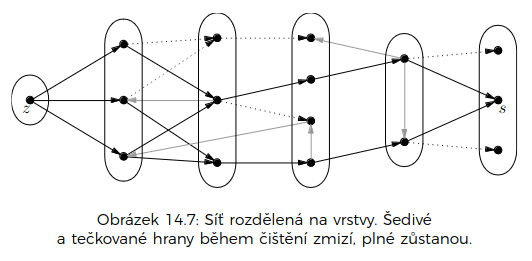

- čištění sítě je celkově v
- každou hranu odstraním nejvýše jednou… duh
- smazaných vrcholů je nejvýše tolik, kolik je smazaných hran

- algoritmus pro hledání blokujícího toku odpovídá prvnímu naivnímu hladovému algoritmu pro hledání maximálního toku, který jsme si ukazovali na začátku – neposíláme záporné toky jako ve FF
- síť je potřeba dočistit – zbavit se slepých uliček tam, kde jsme smazali hranu
- v síti s iracionálními kapacitami existuje maximální tok
- Dinic nevyžaduje nic jako racionalitu hran a je schopen vydat maximální tok pro každou síť
Analýza složitosti
každá fáze trvá
hledání blokujícího toku je celkově v
pro každou orientovanou cestu projdeme nejvýše vrcholů
orientovaných cest je nejvýše
sestrojení sítě rezerv, hledání nejkratší cesty, čistění sítě i zlepšování toku trvají
proběhne fází
- délka nejkratší cesty ze do vzroste po každé fázi alespoň o 1
- je síť rezerv v -té fázi poté, co jsme z ní smazali hrany s nulovou rezervou, ale ještě před pročištěním, její nejkratší cesta ze do je dlouhá
- rozdíl od :
- z každé cesty délky jsme v síti rezerv smazali alespoň jednu hranu (každá musela být zablokována blokujícím tokem)
- žádná z původních cest délky tak v již neexistuje
- z každé cesty délky jsme v síti rezerv smazali alespoň jednu hranu (každá musela být zablokována blokujícím tokem)
- rozdíl od :
- pokud nějaká hrana měla nulovou rezervu a během fáze jsme zvýšili tok v protisměru, rezerva se zvětšila a objevila se hrana v
- vzniklá cesta je ale délky – nově vzniklá hrana se nutně vrací zpátky do vrstvy blíž ke zdroji a navazuje na jinou „dopřednou” hranu
- nejdelší možná cesta mezi a je délky
ve výsledku tedy
Goldbergův algoritmus
- pro síť vezme tak přemrštěné ohodnocení hran, že to ani není tok a následně tyto hodnoty ořezává, až se z nich tok stane
Vlna
Definice: Funkce je vlna v síti , splňuje-li obě následující podmínky
- – vlna nepřekročí kapacity hran
- – přebytek ve vrcholu je nezáporný
- mohou mít přebytky, ale nesmí mít deficity
Převedení vlny po hraně
zavedeme výšky vrcholů
když – existuje přebytek ve vrcholu, existuje rezerva na hraně a je výš než
- tok na hraně zvýšíme o – přeliju to co můžu
Definice: převedení je nasycené, když vynuluje rezervu hrany
- nenasycené převedení vynuluje přebytek
Algoritmus

Poznámky k implementaci
- seznam
- údržba při změně
- výběr v kroku :
- (seznam klesajících hran s kladnou rezervou)
- převedení po je
- zvednutí stojí
- to ale nevadí, zvednutí je dle Z všechna zvednutí trvají
Analýza složitosti
všechna zvednutí trvají
nasycená převedení trvají
nenasycená převedení trvají – počet hran je vyšší než počet vrcholů, takže tohle je ten bottleneck
Invariant A (základní)
- je vlna
- neklesá
- a
Invariant S (o spádu)
-
- neexistuje hrana s kladnou rezervou (nenasycená hrana) a rozdílem výšek (spádem) větším než 1
- zvedáme vždy jen o jedna, jakmile je někde spád 1, dochází k převedení – nikdy se nedostaneme do spádu 2
- neexistuje hrana s kladnou rezervou (nenasycená hrana) a rozdílem výšek (spádem) větším než 1
Lemma K (o korektnosti)
- pokud se algoritmus zastaví, je maximální tok
Důkaz
- algoritmus běží do té doby, dokud existují nějaké přebytky
- když se algoritmus zastaví, vydá tok
- kdyby tok nebyl maximální, podle FF nenasycená cesta ze do
- cesta překonává spád , ale má nejvýše hran
- spor s invariantem S
- cesta překonává spád , ale má nejvýše hran
Invariant C (o cestě do zdroje)
- nenasycená cesta z do
- pro každý vrchol s kladným přebytkem existuje nenasycená cesta do zdroje
Důkaz
- množina všech vrcholů, do kterých vede nenasycená cesta z (a má kladný přebytek)
- chceme ukázat, že
- všechny hrany vedoucí z jsou nasycené (jinak by se dal tok zlepšovat)
- , čímž pádem musí platit
- víme ale, že suma obsahuje kladný člen , bude tedy muset obsahovat i záporný člen
- jediný vrchol se záporným přebytkem je zdroj
- všechny hrany vedoucí z jsou nasycené (jinak by se dal tok zlepšovat)
Invariant H (o výšce)
zvedneme z výšky tehdy, když
- dle C nenasycená cesta z do
- to je dle S spor
- dle C nenasycená cesta z do
Invariant Z (o zvednutí)
- každý vrchol můžu dle H zvednout jen -krát
Lemma Sp (o sytých převedeních)
převedení – převedu po hraně minimum z rezervy hrany a přebytku ve vrcholu
- pokud převedu rezervu hrany, převedení je nasycené
- každou hranu převedu nasyceně maximálně -krát
Důkaz
- uvažme hranu s nulovou rezervou ( je o 1 výše než dle S)
- se musí zvednout alespoň 2krát pro obrácení směru pro převedení přebytku ve ( tím získá rezervu)
- se následně musí zvednout alespoň 2krát pro převedení směru zpět z kopce
- tímto se po každém nasyceném převedení zvětší výška obou vrcholů o 2
- podle H je výška každého vrcholu je nejvýše převedení je nejvýše
Lemma Np (o nenasycených převedeních)
převedení – převedu po hraně minimum z rezervy hrany a přebytku ve vrcholu
- pokud převedu přebytek ve vrcholu, převedení je nenasycené
potenciálový argument
Definice: potenciál – součet výšek vrcholů s přebytkem
- na počátku
- zvednutí
- zvýší přesně o 1
- stane se nejvýše -krát
- Sp
- mohlo se stát, že mělo předtím nulový přebytek, ale nyní jsme ho zvětšili, tedy jeho výška bude započítána do
- mohlo se stát, že mělo předtím nenulový přebytek, ale nyní jsme ho vynulovali, tedy jeho výška zmizí z
- se zvýšil nejvýše o
- všechna nasycená převedení zvýší potenciál maximálně o
- Np
- určitě se vynuluje přebytek , jeho výška z určitě zmizí
- možná se z nulového přebytku stane nenulový, tedy jeho výška bude započítána do
- se snížil alespoň o 1
- potenciál celkově stoupne o a při nenasycených převedení klesá alespoň o 1
- všech nenasycených převedení je
Vylepšení Goldbergova algoritmu
Lemma Np’
- pokud budeme vybírat s největší výškou a , nastane nenasycených převedení
Důkaz
– maximum ze všech výšek vrcholů s přebytkem
fáze končí změnou
- počet zvýšení je dle H max.
- počet snížení je shora omezen počtem zvýšení –
během jedné fáze se každý vrchol účastní maximálně na 1 nenasyceném převedení
po každém nenasyceném převedení po hraně se vynuluje přebytek v
- do už nemůže nic shora přitéct, protože je nejvýše – to zaručuje námi definované vylepšení
počet nenasycených převedení ve fázi
Rychlá Fourierova transformace
Polynomy
- lze reprezentovat jako vektor:
- – velikost polynomu
- – stupeň polynomu
- normalizace: nebo – vyházím počáteční nuly vektorů
Rovnost polynomů
- polynomy jsou identické, pokud mají stejné vektory po normalizaci
- z toho vyplývá rovnost funkcí –
- toto je ekvivalentní!
Věta: Nechť , jsou polynomy stupně max. a pro navzájem různá čísla až . Potom .
Lemma: Pro polynom stupně , počet kořenů je nejvýše
Důkaz věty:
- stupeň a každé z čísel (to je hodnot!) je jeho kořenem
- podle lemmatu musí být nulový polynom, takže
Násobení
pro BŮNO stejně velké a
násobení celkem trvá
Graf polynomu
tentokrát opravdu jen ta křivka
pevně zvolíme až navzájem různých
pomocí nich definujeme polynom velikosti (a stupně ) jako vektor funkčních hodnot v těchto bodech
- toto je jednoznačná reprezentace!
násobení je nyní triviální – pokud , pak
problémky:
- násobení polynomů zvětšuje stupěň
- BÚNO horních koeficientů a jsou nuly (prostě je tam doplníme no)
- jak rychle přejít z koeficientů ke grafu?
- jak rychle přejít z grafů ke koeficientům?
- násobení polynomů zvětšuje stupěň
(Chybné) rychlé vyhodnocování
- polynom můžeme rozložit na členy se sudými exponenty a na ty s lichými:
- navíc můžeme z druhé závorky vytknout :
- v obou závorkách se nyní vyskytují pouze sudé mocniny , proto můžeme každou z nich chápat jako vyhodnocení nějakého polynomu velikosti v bodě :
- pokud do dosadíme hodnotu , dostaneme:
- vyhodnocení polynomu tedy můžeme převést na vyhodnocení polynomů a poloviční velikosti, mohli bychom pak takto pokračovat s dělením velikostí dál
- problém – druhé mocniny reálných čísel jsou vždy nezáporné, v dalších vrstvách by tedy nebylo možné dělení provést
Intermezzo o komplexních číslech
- různé tvary – algebraický, goniometrický, exponenciální
Algebraický tvar
Goniometrický tvar
- číslu říkáme argument čísla – ()
Exponenciální tvar
- z Taylorova rozvoje
- Eulerova formule:
Odmocniny z jedničky
v jednoznačné, v množina!
pozorování: násobení komplexní jednotkou otáčíme číslo o
odmocňování obecně:
některé odmocniny jedničky ale vypadaj líp než jiné (komunismus moment?)
Definice: je primitivní -tá odmocnina z 1 tehdy, když a až
neexistuje menší odmocnina, která by také byla rovna 1
- body které navštívím při mocnění jsou navzájem různé – můžu si je představit jako rozdělovače na jednotkové kružnici v
pro sudé platí
- otočím se jen o půlku původního úseku – půlku jednotkové kružnice
FFT
- polynom budeme vyhodnocovat v bodech , kde je nějaká primitivní -tá odmocnina z jedničky
- hodnoty se od liší pouze znaménkem
- používáme původní chybný algoritmus rozděl a panuj, ale opravujeme ho komplexními čísly

- poslední smyčka od (body 6., 7. 8.) je v
- pak máme logaritmicky mnoho rekurzivních volání
výsledek odpovídá DFT
- Fourierova transformace vektoru lze popsat maticovým násobením:
Inverzní FFT
- maticově:
tato suma je nulová, pokud . Pokud , tedy jsme na diagonále, suma bude rovna .
takže pro zpětný chod použiju také fourierku, ale místo použijeme a nakonec vydělíme
Vzorkování periodických funkcí
Věta: Nechť a . Potom pro všechna
- tím pádem můžeme každý reálný vektor zapsat jako lineární kombinaci navzorkovaných sinů a cosinů
Paralelní algoritmy
Hradlo
- nějaká krabička, která obsahuje nějakou funkci
- má vstupů (hradlo je arity ) a jeden výstup
- – konečná abeceda, typicky
Boolovská hradla
- arita 2 (binární) –
AND,OR,XOR, - arita 1 (unární) –
NOT - arita 0 (konstanty) – 0, 1
Hradlové sítě
- zpracovává jen konkrétní velikost vstupu (oproti běžnému výpočetnímu modelu)
- pro zpracování různých velikostí vstupů máme posloupnost různých hradlových sítí
- neuniformní
Majorita
- vrátí „většinový názor” – je víc nul či jedniček
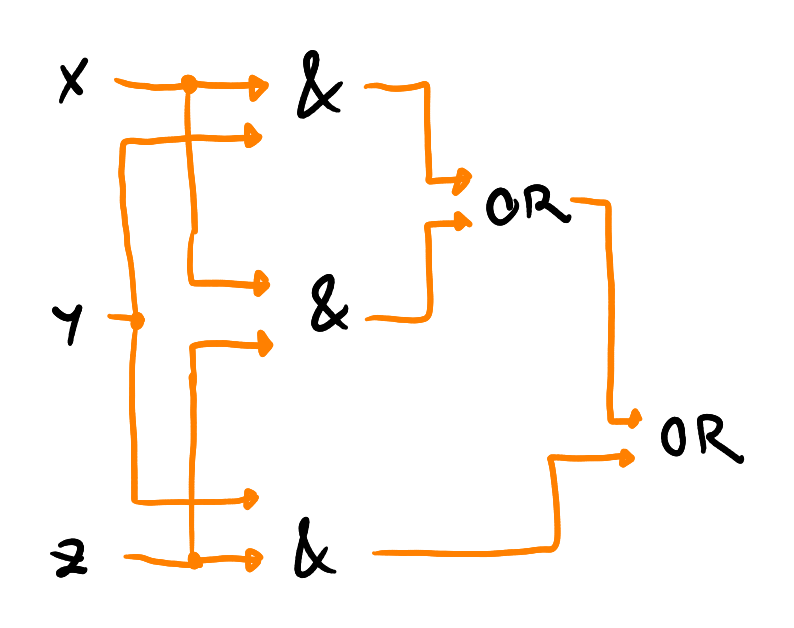
Složení hradlových sítí
- hradla
- vstupní porty
- výstupní porty
- acyklická propojení
Průběh výpočtu
nultý takt – vyhodnotíme vstupní porty a konstanty
i + 1. takt – ohodnotíme hradla a porty, jejichž vstupy byly ohodnoceny nejpozději v i. taktu
to nám síť rozděluje na pomyslné vrstvy
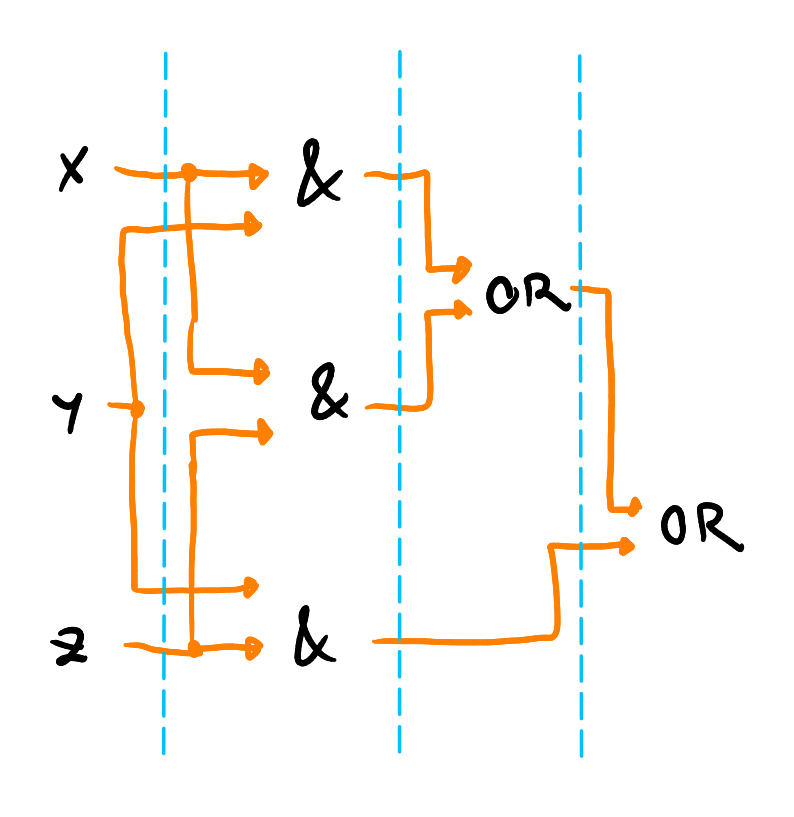
- čas = počet vrstev
- prostor = počet hradel
- musíme omezit aritu nějakou konstantou – jinak bychom mohli definovat hradlo, které řeší obecné problémy v konstantním čase, což je trochu švindl
Posloupnosti hradlových sítí
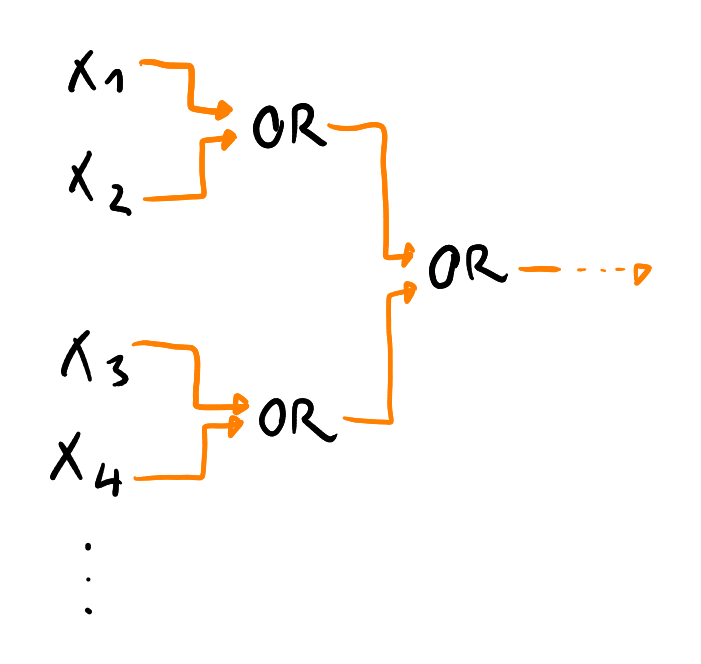
Sčítání
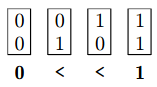
při běžném sčítání nás brzdí čekání na přenosy z nižších řádů
- jak budou vypadat jednotlivá chování jednobitových bloků?
- (1,1) = 1 – přenos určitě nastane
- (0,0) = 0 – přenos určitě nenastane
- (1,0) = < – přenos nastane jen tehdy, když nastal přenos předtím
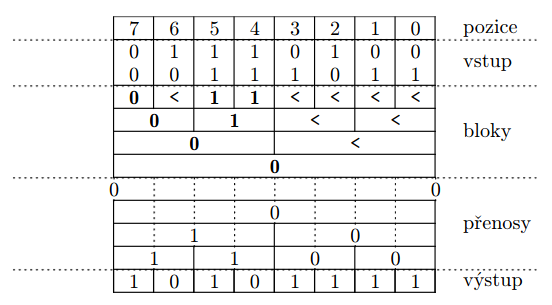
- jak bude vypadat chování kanonických bloků?
- (0,*) = 0 – pokud horní polovina pohlcuje, celý blok pohlcuje
- (1,*) = 1 – pokud horní polovina přenáší, celý blok přenáší
- (<,0) = 0 – horní polovina kopíruje to, co do ní přijde z dolní poloviny
- (<,1) = 1
- (<,<) = <
- jak budou vypadat jednotlivá chování jednobitových bloků?
algoritmus rozdělíme na části:
- spočítáme chování všech kanonických bloků
- nejdříve stanovíme chování bloků velikosti 1, pak velikosti 2, 4, 8, …
- dopočítáme přenosy
- v -tém kroku budou známy přenosy do řádů dělitelných
- paralelně sečtu a přičtu přenosy
- spočítáme chování všech kanonických bloků
Násobení
- násobení dvou -ciferných binárních čísel a :
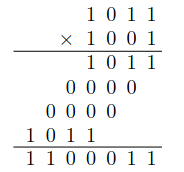
- v binárce je násobení jednou číslicí
AND- paralelně tedy vytvoříme všechna posunutí a jejich
ANDy - zbývalo by sečíst -bitových čísel –
- paralelně tedy vytvoříme všechna posunutí a jejich
Kompresor
- vstup: 3 čísla , a , výstup: 2 čísla a
- pro každý řád spočteme součet – dvoubitové číslo
- = nižší bit tohoto čísla
- = vyšší bit tohoto čísla
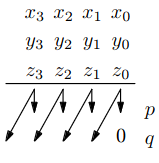
- konstantní!
- máme-li sečíst čísel, v konstantním čase převedeme úkol na sečtení čísel
- dovolí sčítání -bitových čísel v hloubce
Třídění
Komparátorová síť
- hradlová síť složená z komparátorů
- vstup – 2 čísla
- výstup – vlevo menší číslo, vpravo větší číslo
Bubble sort
- čas
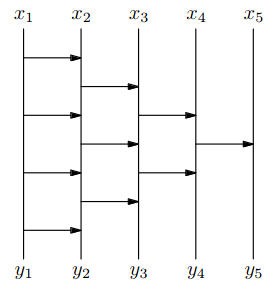
Bitonické třídění
Definice: Posloupnost je čistě bitonická, pokud ji můžeme rozdělit na nějaké pozici na rostoucí posloupnost a klesající posloupnost .
Definice: Posloupnost je bitonická, jestliže ji lze získat rotací nějaké čistě bitonické posloupnosti
Separátor
- rozdělí bitonickou posloupnost na dvě poloviční a navíc jsou všechny prvky v první polovině menší než všechny v té druhé.
- pro zapojíme komparátor se vstupy a
- minimum přivedeme na a maximum na
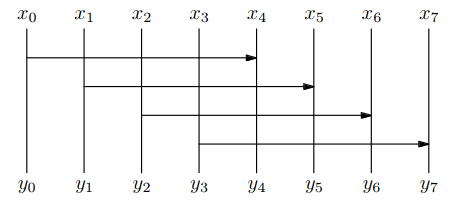
- separátor má zřejmě hloubku 1 a využívá hradel
Důkaz správnosti
- cancerrrrrr
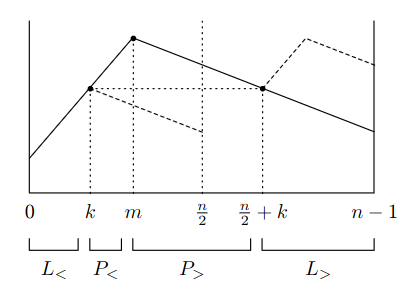
nejdříve předpokládejme, že vstupem je čistě bitonická posloupnost
maximum BÚNO leží v první polovině na indexu (kdyby ne, bude důkaz zrcadlově)
nechť je nejmenší index, pro který komparátor hodnoty a prohodí
maximum je jedinečné, tedy určitě existuje a platí
pro komparátory vždy prohazují
- pro je vidět přímo, pro je
levá polovina vznikne slepením rostoucího úseku s klesajícím úsekem
pravá polovina vznikne slepením klesajícího úseku , rostoucího úseku a klesajícího úseku
obě poloviny jsou bitonické
levá polovina je menší než pravá
- rozdělíme levou polovinu na rostoucí část a klesající část
- rozdělíme pravou polovinu na rostoucí část a
- – obě části původně tvořily rostoucí úsek
- – nejvyšší prvek z je menší než nejnižší prvek z – jinak bychom mohli snížit
- – nejvyšší prvek z je menší než nejnižší prvek z
- – obě části původně tvořily jeden společný klesající úsek
pokud by vstup nebyl čistě bitonický
- separátor je symetrický: zrotujeme-li jeho vstup o pozic, dostaneme o pozic zrotované i obě poloviny výstupu
- pro nečistou bitonickou posloupnost tedy separátor vydá akorát zrotovaný výsledek, což nám nevadí
Bitonická třídička
nejprve separátorem zadanou bitonickou posloupnost rozdělíme na dvě bitonické posloupnosti délky , každou z nich pak separátorem rozdělíme na dvě části délky , atd. atd., až získáme jednoprvkové posloupnosti ve správném pořadí
hladin s komparátory
Bitonická slévačka
- na vstupu dostane dvě setříděné posloupnost délky , vydá setříděnou posloupnost vzniklou jejich slitím
- stačí první posloupnost obrátit, přilepit za tu druhou a setřídit bitonickou třídičkou
- hloubka s komparátory (bottleneck je třídička)
Třídící síť
inspirace v Mergesortu
vstup rozdělíme na jednoprvkových posloupností, které postupně slévačkami sléváme dohromady
celkem provedeme kroků slévání, -tý z nich obsahuje slévačky hloubky
- celková hloubka je tak
- každý krok potřebuje komparátorů, což dává komparátorů
Geometrické algoritmy
Konvexní obal
máme danou množinu bodů, snažíme se nalézt nejkratší uzavřenou křivku, uvnitř níž jsou všechny zadané body
konvexní obal je posloupnost bodů
pro malé počty bodů:
předpoklady:
- všechny body mají navzájem různé -ové souřadnice
- toho můžeme v reálu docílit tím, že si rovinu myšlenkově otočíme o velmi malé po směru hodinových ručiček
- množiny bodů, které měly předtím stejnou -ovou souřadnici se nám nyní uspořádají vzestupně dle jejich -souřadnice
- konvexní obal se skládá z horní a spodní „obálky”
- horní obálka je striktně konkávní, dolní konvexní
- konvexní obal je horní obálka + obrácená dolní obálka
- všechny body mají navzájem různé -ové souřadnice
budeme zametat rovinu zleva doprava a udržovat si horní a dolní obálku

Orientace úhlu
pro každý nový bod potřebujeme zjistit, jestli patří do horní, nebo dolní obálky
pomocí a
- v praxi pomalé a nepřesné
pomocí determinantu
znaménko determinantu určuje orientaci vektorů
pokud jsou navíc hodnoty souřadnic bodů celočíselné, i determinant je celočíselný
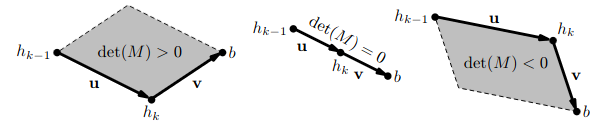
Analýza složitosti
třídění zadaných bodů –
přidání dalšího bodu do obálek je lineární vzhledem k počtu odebraných bodů
- každý bod je ale odebrán nejvýše jednou – přidání je amort.
- všechna přidání jsou celkem
celkem:
Průsečíky úseček
úseček
hledáme všechny průsečíky
- těch může být až , a tak by algoritmus hrubou silou měl být optimální, ne? WRONG!
předpoklady:
- žádné tři úsečky se neprotínají v jednom bodě
- průnikem dvou úseček je nejvýše jeden bod
- krajní bod úsečky neleží na žádné jiné úsečce
- neexistují vodorovné úsečky
budeme zametat rovinu odshora dolů
- neprocházíme celou rovinu, zastavujeme se jen na zajímavých místech – událostech
událost – začátek, konec či průsečík úseček
průřez – množina úseček proťatých zametací přímkou (seřazen zleva doprava)
- pokud si budeme průsečíků všímat jen tehdy, kdy protínající úsečky sousedí v průřezu, nikdy žádný průsečík nemineme
kalendář – naplánované začátky, konce a průsečíky pod zametací přímkou
- začátky a konce úseček můžeme přidat všechny hned na začátku
- průsečíky přidáváme do kalendáře tehdy, když se dvě sousední úsečky v průřezu protínají
- průsečíky odstraňujeme z kalendáře tehdy, když odpovídající dvě úsečky v průřezu přestanou sousedit – jinak bychom mohli několik průsečíků přidat víckrát
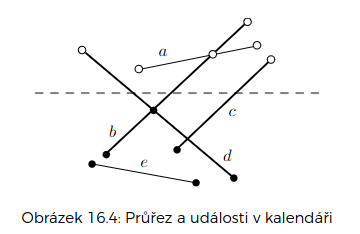

Reprezentace
- Kalendář
- halda nebo BVS
- událostí
- času na operaci
- halda nebo BVS
- Průřez
- potřebujeme vkládat a odebírat úsečky, hledat nejbližší další úsečku vlevo či vpravo od aktuální
- vyvažovaný BVS s úsečkami jako klíči
- úsečka je nalevo od tehdy, když je její průsečík se zametací přímkou více vlevo
- to trochu suckuje, to bych musela přepočítávat furt znova a znova
- úsečka je nalevo od tehdy, když začátek je nalevo od začátku a jejich průsečík není nad zametací přímkou
- pokud je jejich průsečík nad zametací přímkou, je napravo od – to ošetřujeme prohazováním v
- úseček
- času na operaci
- úsečka je nalevo od tehdy, když je její průsečík se zametací přímkou více vlevo
Analýza složitosti
- počet událostí je
- na jednu událost máme konstantní počet operací s datovými strukturami
- jednu událost zpracujeme v čase
- celý algoritmus provedeme v čase a paměti
- existuje algoritmus, který to zvládá v čase
Voroného diagramy
pro množinu míst je systém oblastí , kde obsahuje ty body roviny, jejichž vzdálenost od je menší nebo rovna vzdálenostem od všech ostatních .
2 body – rovina dělená přímkou
3 body – trojmezí
4 body – to už vypadá docela složitě
5 bodů – oh no…
Voroného diagram je rozklad rodiny na konvexní mnohoúhelníky, kde některé jsou otevřeny do nekonečna
diagram připomíná rovinný graf (jen stěny nemusí být omezené)
- vrcholy – body, které jsou stejně vzdálené od alespoň tří zadaných míst (-mezí)
- stěny – oblastí
- hrany části hranice mezi dvěma oblastmi
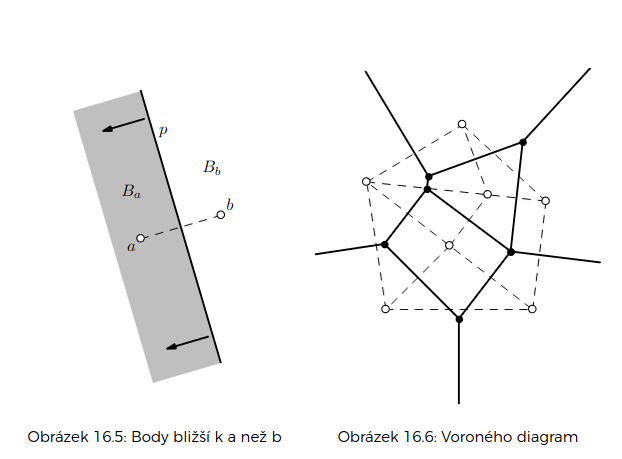
Lokalizace bodu
pokud už máme vybudovaný diagram, jak pro zadaný bod zjistit, do které množiny patří?
zametáme rovinu odshora dolů
- udržujeme si průřez hranic oblastí (podobně jako při hledání průsečíků úseček)
- ten se mění jen při průchodu vrcholy diagramu
- vlastně jsme rozřezali rovinu na pásy, mezi kterými už jsou jen množiny úseček
- když při zametání narazíme na bod, který se snažíme lokalizovat, podíváme se, do kterého intervalu mezi hranicemi průřezu patří
- udržujeme si průřez hranic oblastí (podobně jako při hledání průsečíků úseček)
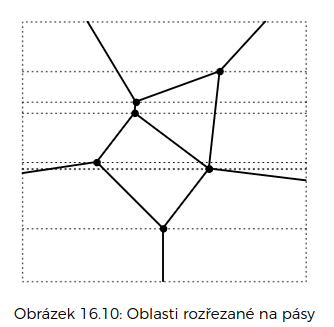
Analýza složitosti
- kalendář i průřez máme opět ve stromech – na dotaz
- hledání jednoho bodu –
- celkově pro dotazů:
- au au au :(
Předvýpočet
předpočítáme si rozdělení roviny na pásy
- pro každý pás známe hranice a průřez (ten je pro každou polohu zametací přímky v pásu stejný)
nyní stačí pro každý bod najít odpovídající pás a jeho polohu v odpovídajícím průřezu
problém: pamatovat si pro každý pás separátní průřez zabírá moc místa – – a je tedy i pomalé
Persistentní vyhledávací stromy
nebudeme průřezy kopírovat, jen si pamatovat jejich „diff”
každá verze má svůj unikátní identifikátor
vezmeme obyčejný AVL strom
- pro novou verzi si zkopírujeme vrchol, který se mění a změníme ho
- musíme změnit ukazatele z jeho otce (a tím ho změnit)
- postupně se dostaneme s každou změnou až do kořene, který se stane identifikátorem verze
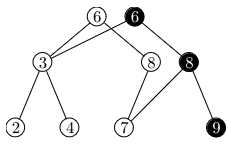
strom předpočítáme v čase a zabírá paměti
lokalizace bodů probíhá v čase
Těžké problémy
Rozhodovací problém
- funkce z – ze všech možných řetězců 0 a 1 na množinu
- zadání každého problému lze zakódovat
- ptám se, jestli něco lze, existuje, …
Bipartitní párování
je dán bipartitní graf a číslo
máme odpovědět, zda v zadaném grafu existuje párování, které obsahuje alespoň hran
jak zakódovat vstup do jedniček a nul?
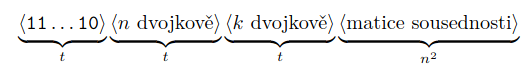
- počet jedniček na začátku kódu nám řekne, v kolika bitech je uložené a a zbytek kódu přečteme jako matici sousednosti
- na všechny nevalidně utvořené vstupy budeme odpovídat
False
problém lze převést na toky – existuje tok velikosti alespoň ?
Převádění
Definice: Jsou-li , rozhodovací problémy, říkáme, že lze převést na (značíme ) právě tehdy, když existuje funkce taková, že pro všechna platí , a navíc lze funkci spočítat v čase polynomiálním vzhledem k . Funkci říkáme převod nebo také redukce.
Lemma: Nechť a je řešitelné v polynomiálním čase, pak je řešitelné v polynomiálním čase
- mějme algoritmus řešící v čase ( je délka vstupu a konstanta)
- mějme převod z na v čase pro vstup délky
- chceme spočítat pro nějaký vstup délky
- nejdříve spočítáme v čase – vyjde výstup délky (delší bychom nestihli vypsat)
- tento vstup pak předáme algoritmu řešící , který nad ním stráví čas
- celkový čas výpočtu proto činí , což je polynom v délce původního vstupu
Převoditelnost jako relace
částečné kvaziuspořádání
reflexivní – umím převést problém sám na sebe
tranzitivní – pokud umím převést na a na , určitě umím převést na
není symetrická – neumím funkci, která vrací vždy
truepřevést na funkci, která vrací vždyfalsenení antisymetrická – umím převést párování na toky
některé třídy jsou ekvivalentní a mezi různými třídami je uspořádání
SAT
satisfiability
- splnitelnost booleovských proměnných
klauzule – závorky
literály – proměnné
je mnoho SAT-solverů, které jsou v praxi docela rychlé
- většina NP-problémů se tak převádí na SAT
CNF
- uvnitř klauzulí je libovolně mnoho literálů, mezi kterými je disjunkce, mezi klauzulemi je konjunkce
- existuje dosazení za proměnné takové, že formule je pravdivá? – splňující ohodnocení
3-SAT
všechny klauzule mají nejvýše 3 literály
3-SAT SAT je triviální
SAT 3-SAT už je zajímavější
SAT 3-SAT
- dlouhou klauzuli lze rozštípnout ve dvě
pokud bylo
true, splňuje první klauzuli a může být klidněfalse, takže pak splňuje druhou klauzulipodobně pro
truepokud je délka původní klauzule , odeberu z klauzule 2 literály, vytvořím pro ně klauzuli a připojím je za původní klauzuli pomocí nějakého nového
tím jsme délku původní klauzule zmenšili o 1
3,3-SAT
- navíc oproti 3-SATu se každá proměnná vyskytuje nejvýše ve 3 klauzulích
3-SAT 3,3-SAT
- nechť je proměnná s výskyty
- rozštípu na nové proměnné a zařídím, aby všechny měly stejnou hodnotu
- klauzule
- lze převést do CNF –
- dokonce umíme takto zařídit, že každý literál je použit nejvýše 2krát
Nezávislá množina
- hledáme v neorientovaném grafu množinu vrcholů velikosti , kde mezi vybranými vrcholy nevede žádná hrana
3-SAT NzMna
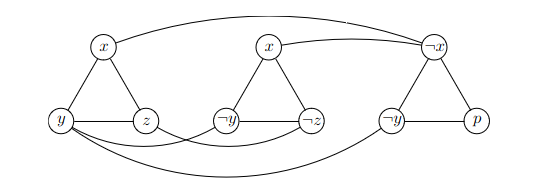
klauzule trojúhelníky
- z každého trojúhelníku můžeme pro NM vybrat pokaždé jen jeden vrchol
hrany mezi a
- může zároveň platit jenom jedno
ohodnocení 3-SATu je splňující tehdy, když je každá klauzule pravdivá
NzMna velikosti
NzMna SAT
nechť vrcholy grafu jsou očíslovány 1 až –
pro každý vrchol si pořídíme proměnnou, která říká, jestli jsme daný vrchol vybrali do NzMna –
pro každou hranu grafu potřebujeme klauzuli, která zakáže, aby i byly zároveň
true- klauzule – alespoň jeden z vrcholů musí být nevybrán
potřebujeme ošetřit
- vytvoříme nějaké očíslování vrcholů nezávislé množiny
- tabulka s řádky a sloupci
- , což lze zapsat pomocí CNF jako
- v žádném sloupci nechceme 2
true– , kde a jsou různé indexy řádků - v žádném řádku nechceme 2
true– , kde a jsou různé indexy sloupců - v každém řádku máme alespoň 1
true–
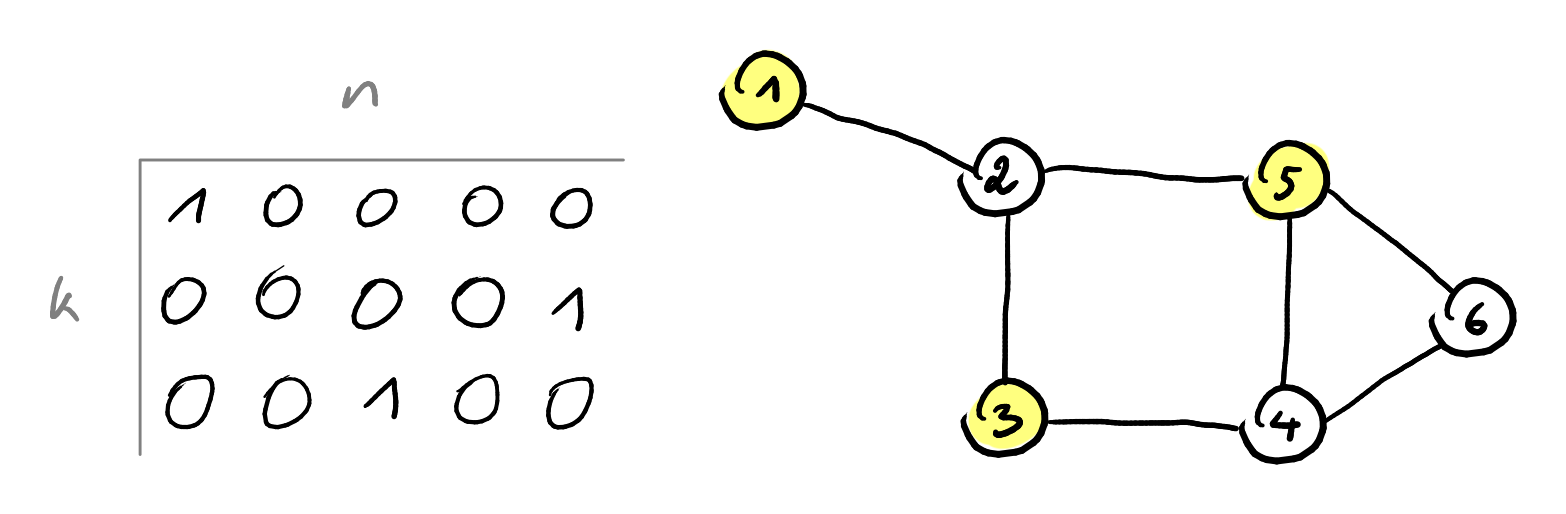
- převod probíhá v polynomiálním čase – vytvoříme polynomiálně mnoho klauzulí a každou z nich stihneme vypsat v lineárním čase
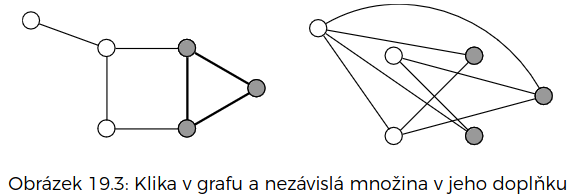
Klika
- hledáme v neorientovaném grafu množinu vrcholů velikosti , kde mezi každou vybranou dvojicí vrcholů vede hrana
- to je taková opačná NzMna – počítáme na hranovém doplňku grafu
3D-párování
3-partitní přiřazení (???)
3 množiny , , a množina
- taký grafík no
snažíme se najít množinu trojic takovou, že každý prvek , , je právě v 1 trojici
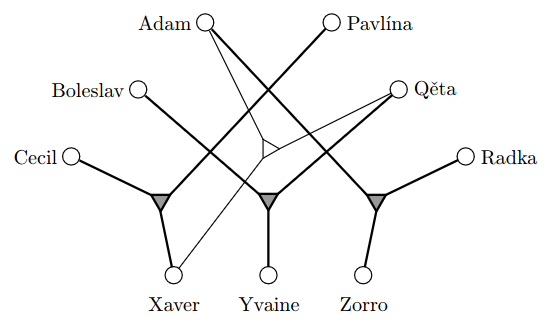
- možná trojice je zakreslená takovým tím trojúhelníčkem s fousy vedoucími k prvkům v trojici
- tmavý trojúhelníček značí trojici, kterou jsme vybrali do výsledné množiny
3,3-SAT 3D-párování
- pokud chceme SAT převádět na jiný problém, potřebujeme obvykle dvě věci:
- konstrukci simulující proměnné – nabývá stavů
TrueaFalse - konstrukci simulující klauzule – splnitelné alespoň jednou proměnnou
- konstrukci simulující proměnné – nabývá stavů
Gadget pro proměnnou
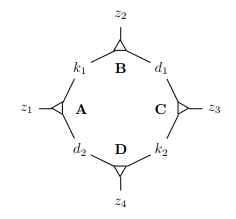
2 kluci, 2 děvčata a 4 zvířátka
- kluci a děvčata hrají roli jen v tomto gadgetu, zvířátka jsou i v ostatních
musí být v nějaké trojici – ,
- spárování a , takže si nesmíme vybrat ani
- pro spárování a musíme vybrat
vždy si musíme vybrat dvě protější trojice v obrázku a druhé dvě nechat nevyužité
- binární – vhodné na reprezentaci proměnných
- – nespáruje zvířátka a
- – nespáruje zvířátka a
Gadget pro klauzuli
- klauzule tvaru
- potřebujeme zajistit, aby nebo bylo 1 nebo 0
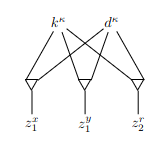
- nová dvojice kluk a dívka – 3 trojice se 3 zvířátky
- zvířátka z gadgetů pro příslušné proměnné
- – zvířátko z Gadgetu pro pozitivní literál (můžeme i , pokud jsme jej nepoužili v jiné klauzuli)
- – zvířátko z Gadgetu pro negativní literál (má před sebou negaci, žeo)
- nějaká zvířátka zbudou :(
- 2 zvířátka jsou SATnuta by default zvolením
True/Falsena gadgetu pro proměnnou - 1 zvířátko je vždy SATnuto výběrem trojice z gadgetu pro klauzuli
- 2 zvířátka jsou SATnuta by default zvolením
- přidáme párů kluk a dívka a pro ně trojice s úplně všemi zvířátky
- i s těmi, co jsou někam zapojená už, prostě úplně úplně úplně se všemi
- zvířátka nedojdou – proměnná se v klauzulích vyskytuje nanejvýš 2krát pozitivně a 2krát negativně
- kdyby se vyskytovala 3krát se stejnou hodnotou, pak je ohodnocení těchto klauzulí triviální a můžeme je trashnout
- zvířátka z gadgetů pro příslušné proměnné
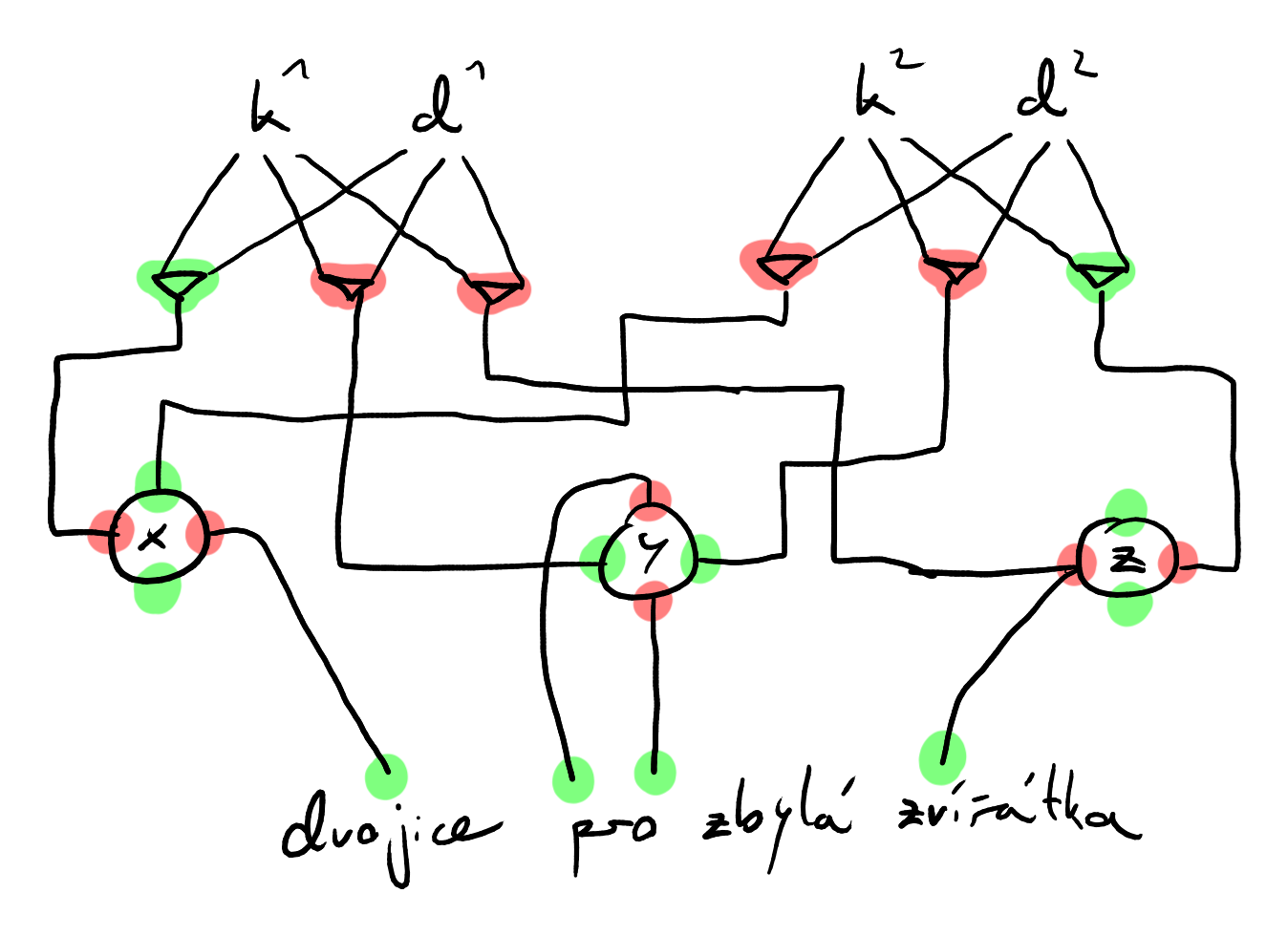
- zapojení pro výrok
- zeleně jsou označeny trojice, které jsme vybrali, červeně ty, které jsme nevybrali
- do
dvojice pro zbylá zvířátkave skutečnosti vede daleko více hran, jen tam nejsou nakreslené - a jsou
True, jeFalse
Složitostní třídy
Třída P
Definice: Problém leží v tehdy, když existuje nějaký algoritmus a polynom , přičemž pro každý vstup algoritmus doběhne v čase nejvýše a vydá výsledek
Třída NP
Definice: je třída rozhodovacích problémů, v níž problém leží tehdy, když existuje nějaký problém a polynom , přičemž pro každý vstup je právě tehdy, když pro nějaký řetězec délky nejvýše platí
- Algoritmus řeší problém , ale kromě vstupu má i nápovědu (např. splňující ohodnocení SATu)
- pokud , pak , kterou by schválilo
- pokud , pak , kterou by schválilo

- alternativní definice: nedeterministicky polynomiální
deterministický – všechno je důsledkem předem daných událostí, takto fungují všechny naše stroje
nedeterministický – můj program se může chovat náhodně a nějaká větev výpočtu se dobere výsledku, neumíme simulovat
NP certifikáty
řetězec je certifikát stvrzující kladnou odpověď – třeba seznam proměnných se splňujícím ohodnocením pro SAT
- o negativní odpovědi nevíme vůbec nic (ty říkají něco o problémech v )
polynomiální algoritmus má za úkol certifikáty kontrolovat
NP-hard
Definice: Problém je -těžký tehdy, když každý problém , lze převést na
NP-complete
Definice: Problém je -úplný tehdy, když je -těžký a navíc
Lemma: pokud je -těžký, pak
nechť
(díky -těžkosti)
… proto $\text{NP} \supseteq \text{P}
logické
- SAT
- 3-SAT
- 3,3-SAT
- obvodový SAT (pro hradlové sítě)
grafové
- nezávislá množina
- klika
- vertex cover
- k-obarvitelnost
- hamiltonovské cesty a kružnice
- 3D-párování
číselné
- součet podmnožin
- hledáme podmnožinu přirozených čísel, která se sečte na zadané číslo
- problém batohu
- 2 loupežníci
- jde množina rozdělit na 2 podmnožiny tak, aby měly stejnou cenu?
- nula jedničkové lineární rovnice
- hledáme řešení, které obsahuje jen nuly a jedničky
- stále počítáme v !
- součet podmnožin
Cook-Levinova věta
Věta: SAT je -úplný
Lemma: Nechť je problém ležící v . Potom existuje polynom a algoritmus, který pro každé sestrojí v čase hradlovou síť s vstupy a jedním výstupem, která řeší .
- intuice – počítače jsou jakési složité booleovské obvody, jejichž stav se mění v čase
- uvažme nějaký problém a polynomiální algoritmus, který jej řeší
- pro vstup velikosti algoritmus doběhne v čase polynomiálním v a spotřebuje paměti
- stačí nám tedy „počítač s pamětí velkou ”
- booleovský obvod velikosti polynomu v a tedy i v
- vývoj v čase – sestrojíme kopií tohoto obvodu, každá z nich bude odpovídat jednomu kroku výpočtu a bude poropojená s minulou a budoucí kopií
- máme booleovský obvod, řešící problém pro vstupy velikosti , který je polynom. velký vzhledem k
Úprava definice NP: Budeme chtít, aby nápověda měla pevnou velikost závislou pouze na velikosti vstupu: (napísto předchozího )
- úprava je BÚNO (stačí původní nápovědu doplnit na požadovanou délku nějakými „mezerami”)
NP-úplnost obvodového SATu
na vstupu je hradlová síť s vstupy a jedním výstupem
- můžeme přivést na vstupy takové hodnoty, aby byl výsledek
True?
- můžeme přivést na vstupy takové hodnoty, aby byl výsledek
obecnější než běžný SAT
je v – stačí si nechat poradit vstup, udělat toposort sítě a spočítat hodnoty hradel
je v –hard
- mějme , o němž chceme dokázat, že se dá převést na obvodový SAT
- když nám někdo předloží vstup délky spočítáme velikost nápovědy
- algoritmus kontrolující správnost nápovědy je v
- dle lemmatu umíme sestrojit obvod, který pro konkrétní velikost vstupu počítá to, co
- vstupem je a nápověda
- výstup je, zda je nápověda správná
- velikost obvodu je také polynomiální –
- v obvodu zafixujeme vstup , čímž máme obvod se vstupem jen
- můžeme za dosadit nějaké hodnoty, aby na výsledku bylo
True?- doslova otázka jak při převádění
- můžeme za dosadit nějaké hodnoty, aby na výsledku bylo
- pro libovolný problém z dokážeme sestrojit funkci, která pro každý vstup v polynomiálním čase vytvoří obvod splnitelný právě tehdy, když odpověď tohoto problému na vstup má být kladná
- to je doslova převod z daného problému na obvodový SAT
Obvodový SAT 3,SAT
- budeme postupně budovat formuli v CNF
- každý booleovský obvod se dá v polynom. čase převést na ekvivalentní obvod pouze za pomoci hradel
ANDaNOT- stačí najít klauzule odpovídající těmto hradlům
- pro každé hradlo v obvodu zavedeme novou proměnnou popisující jeho výstup
- v polynomiálním čase jsme schopni vytvořit formuli, která je splnitelná právě tehdy, když je splnitelný zadaný obvod
NOT
- na vstupu máme proměnnou a na výstupu
- přidáme klauzule, které nám zaručí, že jedna proměnná bude negací té druhé
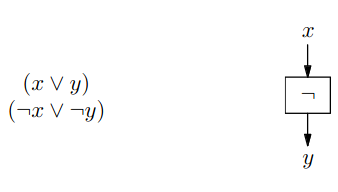
AND
- na vstupu máme proměnné a , na výstupu
- potřebujeme přidat klauzule, které nám popisují, jak se toto hradlo má chovat
- lze je převést do CNF
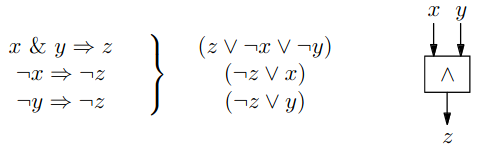
Co s NP-úplným problémem?
- malé vstupy
- stačí problém umlátit vhodně ořezaným exponenciálním algoritmem
- speciální vstupy
- na stromech – většinou lineární
- na bipartitních grafech – většinou bude existovat polynomiální algoritmus (často odvozený od toků v sítích)
- aproximační algoritmy – existuje docela dobrá aproximace v polynomiálním čase
- umíme vždy dobře říct, jak daleko je aproximace od optima
- heuristické přístupy – v některých případech bude výsledek fajn, jindy fakt mizerný
- neumíme říct, jak daleko je výsledek od optima
- kombinace
- heuristické řešení může rozdělit problém na malé podproblémy, které řeší optimálně v exponenciálním čase
- aproximační algoritmus si může zkusit pomoct heuristikou pro nalezení potenciálně lepšího řešení
Největší nezávislá množina ve stromu
Lemma: Je-li strom (funguje i pro lesy 🌲🌳) a jeho list, pak alespoň 1 největší nezávislá množina obsahuje
- nechť je nějaká největší nezávislá množina a je list
- buďto a máme hotovo
- jinak musí mít nějakého souseda , který musí být v (jinak bychom mohli přidat a by nebyla největší)
- je také největší nezávislá množina
- tímto způsobem můžeme pokračovat pro všechny listy
Algoritmus
- do nezávislé množiny budeme přidávat při zpětném průchodu DFS v zakořeněném stromu

Barvení intervalového grafu
- máme rozvrh hodin přednášek
- rozdělujeme přednášky mezi posluchárny tak, abychom použili co nejmenší počet poslucháren
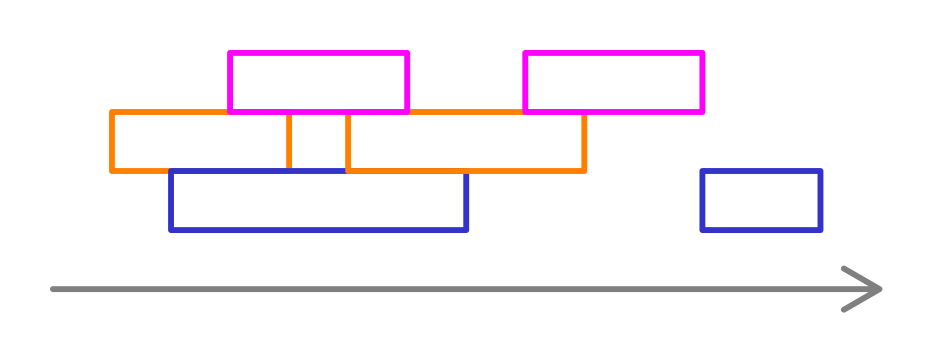
Intervalový graf:
Algoritmus
- budeme zametat časovou přímku bodem a všímat si událostí – začátky a konce přednášek
- kdykoliv interval začne, přidělíme mu barvu, kdykoliv skončí, barvu uvolníme
- dalším intervalům budeme přednostně přidělovat volné barvy před přidělováním nových barev

- algoritmus opravdu použije nejmenší počet barev
- v momentě, kdy bychom potřebovali přidat další barvičku, jsme někdy v minulosti vytvořili barev, které nyní využíváme, což znamená, že před aktuálním momentem se protínalo intervalů. Přidáním dalšího intervalu pak protínáme intervalů, takže potřebujeme barviček
Problém batohu s malými čísly
Předměty
Hmotnosti
Ceny
Nosnost batohu
Hledáme podmnožinu předmětů, která se vejde do batohu a její cena je největší možná
problém batohu je řešitelný polynomiálně tehdy, když ceny všech předmětů jsou malá celá čísla
- chceme polynomiální algoritmus závislý na a
Definice: minimum z hmotností těch podmnožin velikosti , které jejichž cena je právě
pokud žádná taková podmnožina neexistuje,
dynamické programování
- optimální řešení pro předmětů získáme přidáním vhodného předmětu pro optimální řešení pro předmětů
- matematicky zapsáno:
- přechod od k trvá – celou tabulku vyplníme v čase
- maximální cena množiny, která se vejde do batohu, je největší , pro které je
- nalezení tohoto nás stojí čas
- optimální řešení pro předmětů získáme přidáním vhodného předmětu pro optimální řešení pro předmětů
ještě potřebujeme znát prvky v batohu
- stačí si udržovat spojový seznam přidaných předmětů
problém řešíme v čase
- pseudopolynomiální – je polynomem vůči a , ale není polynomem vůči velikosti vstupu ( může být v binárce až exponenciálně velké, proto funguje jen s malými čísly)
Aproximační algoritmy
máme nějakou množinu přípustných řešení a každé z nich ohodnoceno cenou
mezi nimi hledáme optimální řešení s minimální cenou
vystačíme si s -aproximací – přípustné řešení má cenu pro
- relativní chyba nepřekročí
poměrová chyba – poměr mezi výstupem a optimem je nejvýše
relativní chyba – rozdíl mezi výstupem a optimem je … idk?
TSP – Problém obchodního cestujícího
neorientovaný graf
- hrany ohodnoceny délkami
chceme najít nejkratší hamiltonovskou kružnici
nechť je úplný a platí trojúhelníková nerovnost
2-aproximace
mějme minimální kostru grafu
projdeme kostru – hran
- tím jsme nedostali kružnici, nýbrž sled
- upravíme – kdykoliv se při průchodu dostaneme do již navštíveného vrcholu, „přeskočíme” jej a přesuneme se až do nejbližšího dalšího nenavštíveného vrcholu
- díky trojúhelníkové nerovnosti existují zkratky mezi vrcholy, které nám umožní kostru „obejít”
- tím jsme nedostali kružnici, nýbrž sled
Pozorování: – když z nejkratší hamiltonovské kružnice smažeme hranu, získáme minimální kostru
- výstup
Nutnost trojúhelníkové nerovnosti
Věta: TSP nejde bez trojúhelníkové nerovnosti aproximovat (jinak by platilo )
mějme graf , doplňme jej na úplný graf
- pokud je v hrana, tatáž hrana bude v grafu , ale s délkou 1
- pokud v daná hrana není, bude v s délkou
původní HK: délka
nové HK: délka
pokud nastavíme dostatečně vysoké, mezera mezi a bude i přes -aproximaci znatelná
dokážeme v polynomiálním čase rozhodnout, jestli v je HK
Problém batohu s velkými čísly
kapacita batohu
předměty :
- hmotnosti
- ceny
chceme t.ž. a je maximální
kdybychom měli zadání ve vysokých číslech, která jsou všechna dělitelná nějakým číslem, můžeme si je přeškálovat a řešit polynomiálním algoritmem v nízkých číslech
- když nejsou čísla škálovatelná, jejich vydělením můžeme způsobit nepřesnost
rozsah cen při škálování pro (nakvantované značíme )
- každou cenu vynásobíme poměrem a zaokrouhlíme
- to je to samé, jako kdybychom jednotlivé ceny zaokrouhlili na násobky čísla
- každé jsme tím změnili nejvýše o
- po zahození předmětů s , má optimální řešení původní úlohy cenu
- chyba aproximace nepřesáhne (kde je počet vybraných předmětů)
- má-li chyba být shora omezena , musíme zvolit
- každou cenu vynásobíme poměrem a zaokrouhlíme

- když budeme hmotnosti zaokrouhlovat dolů, celé se to rozbije – mohli bychom generovat nepřípustná řešení původní úlohy (předměty se do batohu nevejdou)
- ceny zaokrouhlovat dolů můžeme
Analýza složitosti
- kroky 1–3 a 5 zvládneme v
- krok 4 řeší problém batohu se součtem cen , což stihne v čase
Analýza chyby
– optimální řešení původní úlohy
– optimální řešení přeškálované úlohy
chceme – tedy chceme -aproximaci
jakou cenu má optimální řešení původní úlohy v nakvantovaných cenách?
optimální řešení v nakvantovaných cenách má cenu alespoň jako řešení v původních cenách krát poměr kterým škálujeme mínus počet prvků, se kterými pracujeme
- zaokrouhlování u jednoho prvku způsobí chybu nejvýše 1, čili dohromady nejvýše
jakou cenu má optimální řešení přeškálované úlohy v původních cenách?
první nerovnost platí proto, že ceny zaokrouhlujeme dolů – původní ceny jsou větší nebo rovny přeškálovaným cenám
poslední nerovnost platí proto, že je optimální řešení kvantované úlohy, zatímco je nějaké další řešení téže úlohy, které nemůže být lepší
když složíme obě nerovnosti dohromady a dosadíme na :
první nerovnost platí díky dosazení za
- zlomek se odečítá a potenciálně zmenšuje, čili nerovnost je ve správném směru
druhá nerovnost platí proto, že
- já odčítám, takže ta nerovnost je ve správném směru
Existuje algoritmus, který pro každé nalezne -aproximaci problému batohu s předměty v čase
Aproximační schéma
aproximujeme úlohu se zadaným , které nám říká omezení na chybu
PTAS – Polynomial-Time Approximation Scheme
- algoritmy, které pro každé najdou v polynom. čase -aproximaci optimálního řešení
- aproximace s chybou
- algoritmy, které pro každé najdou v polynom. čase -aproximaci optimálního řešení
FPTAS – Fully Polynomial-Time Approximation Scheme
- máme zaručeno, že je to polynomiální i s
- čas
- máme zaručeno, že je to polynomiální i s