Úvod do kryptografie
Toto jsou moje poznámky z předmětu “Úvod do kryptografie,” který přednášel Mgr. Martin Mareš, Ph.D. Výuka probíhala v angličtině, je tedy dost možné, že jsou některé termíny v mých poznámkách přeloženy nepřesně.
Více informací o předmětu naleznete zde.
Kryptografické útoky
Druhy útoků
- known ciphertext
- známe jen zašifrovaný text
- chceme zjistit plaintext
- known plaintext
- známe nějaký plaintext a jeho zašifrovanou verzi
- chceme zjistit klíč
- chosen plaintext
- oproti known plaintextu si jej můžeme zvolit
- chceme zjistit klíč
- rozlišovací útoky
- chceme zjistit, jestli zašifrovaný text koresponduje s určitým typem plaintextu
- např. když šifra leakuje délku plaintextu
Jak měřit obtížnost útoku
- Security level (v bitech)
- na prolomení šifry potřebujeme pokusů
- pozorování:
„Narozeninové” útoky
- některé protokoly nebo šifry jdou docela dobře umlátit překvapivou pravděpodobností
Challenge–response autentikace
- různých noncí (nonce = number only once)
- kolik pokusů v průměru potřebujeme, než se nonce zopakuje?
- pravděpodobnost, že náhodná funkce z (pokusy) do (nonce) je prostá
-
- aproximujeme a tedy
- pro
- to znamená, že
- security level funkce s je poloviční než velikost klíče
Welcome message
protokol:
Alice vygeneruje náhodný klíč a pošel jej po side-channelu Bobovi
Alice pošle welcome message (známý plaintext) šifrované klíčem
Pak posílá další zprávy šifrované klíčem
útočník si může předpočítat uvítací zprávy pro náhodných klíčů (množina )
- pak poslouchá relací a čeká, až se objeví některý z předpočítaných klíčů

pro je to jen nějaká docela reasonable konstanta
trade-off mezi časem na předvýpočet a délkou samotného útoku
Jednorázové klíče
Vernamova šifra a.k.a. One-time Pad
zpráva
perfektně náhodný klíč
zašifrovanou zprávu získáme pomocí funkce (tím i dešifrujeme, protože je sám sobě inverzní)
- – šifrovací fce, – dešifrovací fce
pozor! zprávu nikdy nesmíme zopakovat klíč
- útočník může zprávu triviálně měnit
- pro dvě zprávy a klíč –
- Sověti ve WW2 whupsík dupsík
- útočník může zprávu triviálně měnit
pokud nám zašifrovaný text nedává žádnou informaci o plain textu, šifra je perfektně bezpečná
Věta: pokud má perfektně bezpečná šifra -bitové zprávy a -bitové klíče, pak
- to znamená, že One-time Pad je to nejlepší, co můžeme mít
Důkaz:
- angličtina wat
- množiny všech plaintextů a všech zašifrovaných textů jsou velikosti
- počet možných klíčů je – čili počet možných zobrazení mezi těmito množinami
- pro spor předpokládejme, že
- pak a musí existovat nějaké 2 plaintexty a a zašifrovaný text , že je možné zašifrovat na pomocí nějakého klíče, ale nikoliv
proto ,
ale
- rozdělení není rovnoměrné a šifra není perfektně bezpečná, spor
Dělení tajemství
- zpráva zašifrovaná několika klíči – musíme mít všechny klíče, abychom byli schopni zprávu dešifrovat
- je komutativní, nice
-prahové schéma
a.k.a. Shamir scheme
rozděluje zprávu na částí tak, že:
- libovolných částí určí celé tajemství
- žádných částí nic neprozradí
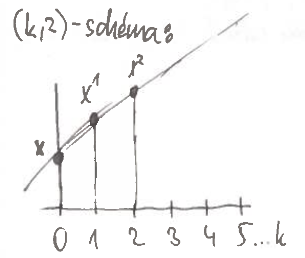
- hledám takové, že:
- a ( znamená, že volba je perfektně náhodná)
- taková existuje právě 1
- pak volím
- a ( znamená, že volba je perfektně náhodná)
- libovolná dvě jednoznačně určí , ale pokud známe jen , všechna jsou stejně pravděpodobná
- každému odpovídá právě jedna
Obecně
- polynom stupně menšího než nad konečným tělesem (uvažujeme )
- volím náhodně
- rozdám části až
- pokud znám částí, určím jednoznačně (Lagrangeova interpolace)
- pokud znám částí:
- pokud libovolně nastavím dalších částí, každá volba určí právě jednu
- všechna jsou stejně pravděpodobná (yippeee)
- pokud libovolně nastavím dalších částí, každá volba určí právě jednu
Symetrické šifry
Proudové
- generují keystream, se kterými se data xorují
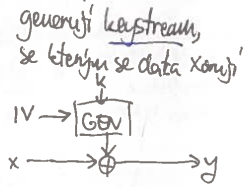
- vlastně Vernamova šifra s pseudonáhodným generátorem
- – funkce pro šifrování a dešifrování je ta stejná ( je komutativní)
- přehození bitu přehodí
- NIKDY!! nechceme opakovat IV
Blokové
- šifrují bloky pevné délky
- permutace na
- delší zprávy šifrujeme po blocích a případně přidáváme padding
Bezpečnost
- velmi těžké definovat formálně
- Idea: šifru nelze efektivně rozlišit od náhodné permutace
- verifikátor dostane orákulum, které vrací buďto pro náhodné , nebo náhodnou permutaci
- úkol verifikátoru je říct, kterou variantu vrací
- může pokládat více dotazů
- chceme, aby nešla dosahnout s lepší složitostí než
- TLDR: dobrá bloková šifra je ta, která vypadá docela náhodně
- reálné šifry jsou prakticky vždy sudé permutace (lolol)
- verifikátor dostane orákulum, které vrací buďto pro náhodné , nebo náhodnou permutaci
- tohle nepokrývá chosen-key/related-key útoky :(
Iterovaná šifra
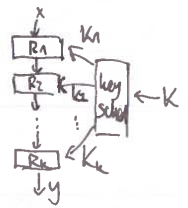
substitučně-permutační sítě
- během jednoho kola:
- vstup se vyxoruje s tajným klíčem (kde je číslo kola)
- whitening – omezuje kontrolu útočníka nad vstupy do S-boxů
- výstup se přesměruje do mnoha S-boxů – confusion
- malé invertibilní tabulky
- permutace na hodnotách vstupu
- výstupy s-boxů se spojí do P-boxu – diffusion
- permutace na pozicích S-boxů v bloku
- také invertibilní, stačí použít inverzní permutaci
- vstup se vyxoruje s tajným klíčem (kde je číslo kola)
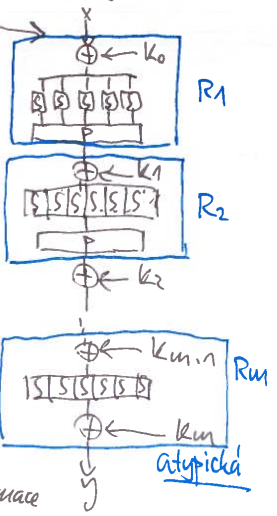
- všechny části šifry jsou invertibilní
- xor a P komutují, můžeme tak xory a P správně popřesouvat a najednou máme znova SPN
- inverze SPN je opět SPN!
Feistelovy sítě
- konstrukce s neivertibilními S-boxy
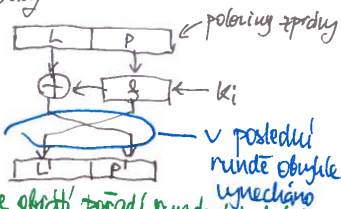
- zprávu rozdělíme na 2 poloviny
- pravou polovinu zakódujeme pomocí neinvertibilní a tajného klíče
- Feistelova funkce – může být libovolná
- prohodíme pravou a levou polovinu a pokračujeme od bodu 2
- inverze je zase Feistelova síť, jen se obrátí pořadí klíčů
DES (Digital Encryption Standard)
- vyvinut začátkem 70. let v IBM na zakázku NBS
- do vývoje mluvila NSA
- 56-bitový klíč (technicky 64, ale každý byte má parity bit)
- Feistelova síť s 16 iteracemi
- NSA na poslední chvíli vyměnila S-boxy (sus)
- dnes už víme, že tím actually šifru zesílila proti diferenciální kryptoanalýze (technika, která se ale objevila až daleko později, huhmm)
Struktura DESu
feistelova síť s 16 koly pracující s 32-bitovými půlbloky
plus máme na začátku a na konci P-box navíc
- úplně zbytečný, navíc znepříjemňuje SW implementaci
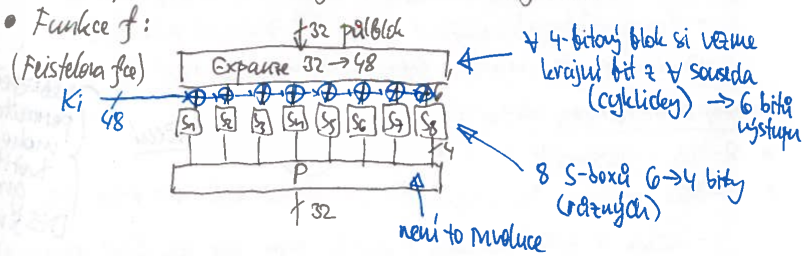
funkce :
- expanduje 32 bitů na 48
- 4-bitový blok si vezme krajní bit z každého souseda (cyklicky) 6 bitů výstupu
- 8 xorů se vstupním tajným klíčem
- 8 lossy S-boxů – 6 bitů vstupu 4 bity výstupu
- P-box
- expanduje 32 bitů na 48
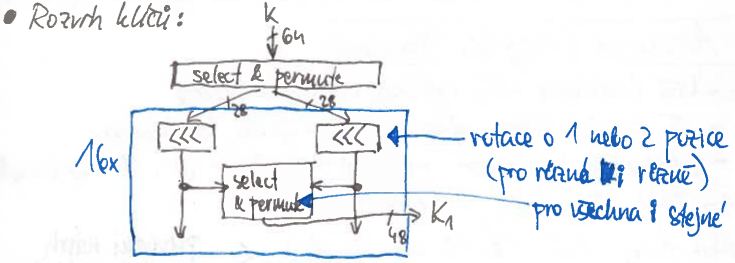
- rozvržení klíčů mezi iteracemi
- dostane na vstupu 56b klíč a vyprodukuje 16 klíčů o 48 b
- každý klíč obsahuje podmnožinu vstupního klíče v nějaké permutaci
- dostane na vstupu 56b klíč a vyprodukuje 16 klíčů o 48 b
Kritika DESu
- slabé klíče
- pokud , pak všechny
- enkrypce je identická s dekripcí – oof size max
- podobně pro samé jedničky a asi 2 další klíče
- pokud , pak všechny
- doplňky se ve Feistelově funkci (konkrétně při xorování) vyruší
- xorování s levou částí pak produkuje invers
- klíče jsou příliš krátké
- už v roce 1977 se odhadovalo, že lze postavit stroj, který vyzkouší všechny klíče za 1 den
- jen o 20 let později se to povedlo
- v roce 2012 to dokonce byla služba – mohli jste si koupi prolomení DESu na zakázku
- krátké bloky – kolize bloků jednou za bloků
Útoky na DES
- diferenciální kryptoanalýza – stačí chosen plaintextů
- lineární kryptoanalýza – dokonce jen chosen plaintextů
- to je dost na to, abychom šifru považovali za rozbitou
Pokusy o záchranu DESu
- devadesátá léta
- zkoušela se konkatenace DESu
- 2-DES – nepomůže
- sice zdvojnásobuje keysize, ale sec. level
- 3-DES – sec. level 113
- 2-DES – nepomůže
AES (Advanced Encryption Standard)
- 1997 – NIST (nástupce NBS) vypisuje otevřenou soutěž
- 15 návrhů šifer, několik kol veřejného hodnocení
- kritéria: bezpečnost, rychlost + snadnost na SW i HW implementaci
- vítěz: Rijandel – 2001
Struktura
- 128-bitové bloky
- variabilní délka klíče – 128, 192 nebo 256
- z toho se pak odvozuje počet kol – 10, 12 a 14
- SPN s lineární transformací
- bajtově orientovaná (pro efektivní implementaci v SW)
- každý blok má tvar matice bajtů, klíč pro každou iteraci má stejný tvar
Iterace
ByteSub:
- bajty stavu proženeme identickými S-boxy
- S-box je inverze v galoisově tělese + afinní transformace z rotací a
XORů
- S-box je inverze v galoisově tělese + afinní transformace z rotací a
- bajty stavu proženeme identickými S-boxy
ShiftRow – -tý řádek rotujeme o nějaký počet bajtů doleva
MixColumn – na každý sloupec aplikujeme stejnou invertibilní lineární transformaci
- není v poslední iteraci
AddRoundKey –
XORs klíčem- před 1. iterací dám navíc jeden AddRoundKey
- vylepšená implementace na 32-bitových procesorech
- 4 lookupy kombinující S-box s částí MixColumns
- každý sloupec je
XOR4 lookupů v tabulkách
- každý sloupec je
- na dnešních procesorech se dají některé implementace napadnout kvůli cacheování
- 4 lookupy kombinující S-box s částí MixColumns
Inverzní iterace
- některé části AES komutují
- InvMixColumn
- AddRoundKey (s nahrazeným klíčem)
- InvMixColumn komutuje s AddRoundKey, pokud nahradíme jeho mixem
- InvByteSub
- InvShiftRow komutuje s InvByteSub
- InvShiftRow
- jen orotovaná běžná iterace
Rozvrh klíčů
- pracuje po 32-bitových slovech
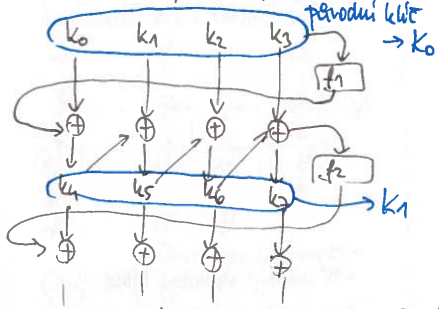
- je postavena z S-boxu /stejný jako šifrovací), rotace o 1 bajt a přimíchávání konstanty
Kritika AES
- jednoduchá algebraická struktura
- je možné, že se někdy najde způsob, jak tyto struktury efektivně rozbíjet řešením rovnic
- příliš malá rezerva v počtu iterací
- po nějakém čase budeme nejspíše umět rozbíjet rychleji
- jelikož je AES optimalizovaný na rychlost
- zarovnaná na byty
- difuze je až moc kontrolovaná
- i přes to se ale zatím žádný zajímavý útok neumí (krom těch implementačních, hehe)
- 128-bitový klíč není bezpečný proti kvantovým počítačům (Groverův algoritmus)
- haha, pokud věříme, že se to
- 128-bitové bloky jsou moc malé
- kolizní útoky po blocích
- stačí změnit klíč po blocích
- máme daleko méně času na to najít kolizi
- dobrá praktika in general
Použití blokových šifer
- jak šifrovat zprávy, jejíchž délka není dělitelná velikostí bloku
Padding
musí být reversibilní – nevíme totiž, jaká byla předchozí délka zprávy
varianty:
první byte paddingu je nějaká konstanta, pak doplníme samé nuly
celý padding je konstanta P = délka paddingu
celý padding jsou nuly až na poslední byte, který je P = délka paddingu
jak ale poznáme, jestli jsme přijali nepoškozenou zprávu? (chceme kontrolovat formát paddingu)
Módy blokových šifer
ECB
- Electronic Code Block
- každý blok zakódujeme stejnou funkcí a výsledky poslepujeme ve stejném pořadí dohromady
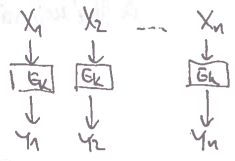
velmi jednoduché (a velmi rozbité, nepoužívat)
- leakujeme, jestli jsou nějaké bloky stejné
- nemáme žádnou náhodnou vstupní hodnotu, takže při znalosti jsme v loji
zajímavé vlastnosti:
- random access encryption i decription
- každý blok je nezávislý na ostatních blocích – možnost paralelizace
- bit-flip v rozbije původní informace , ale nijak neovlivní pro
- pokud prohodíme a , prohodíme i a
- random access encryption i decription
CBC
- Cipher Block Chaining
- haha řetízkový blokotoč yeee
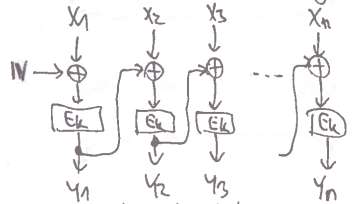
první blok vstupu vy
XORujeme s náhodným inicializačním vektoremIVa proženemenásledně každý další blok vstupu cy
XORujeme s předchozím blokem výstupu a proženemezajímavé vlastnosti:
- random access decription (ale né encryption)
- bit-flip v změní celý a jeden bit v
- vynechání/prohození dvou bloků ovlivní tyto bloky a 1 následující
Leaking
- narozeninový paradox: po blocích máme pravděpodobně pro
- útočník si všiml, že se zopakovaly bloky a
- ze
XORu předchozích bloků získá bitů informace o plaintextu
- ze
- dokud nešifrujeme moc velké zprávy, je tento leak docela vpohodě
CTR
- Counter
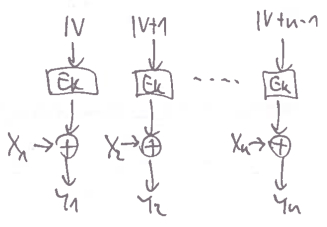
proudová šifra – padding není potřeba
nikdy nesmíme zopakovat
IV!!- bylo by to jako zopakovat one-time pad
- oproti CBC ale není potřeba, aby
IVbyl náhodný
zajímavé vlastnosti:
- bit-flip v udělá akorát bit-flip v
- random access encryption i decription
- možná paralelizace v obou směrech
Leaking
- kolik toho leakujeme, pokud jsou všechny bloky různé?
pro každou dvojici plaintextových bloků leakujeme maličkou informaci
- původní počet možností byl , nyní je
decrease in entropy:
- pro každou dvojici bloků leakujeme informace
- celkový leak pro počet bloků
- leak by se rovnal tomuto číslu, kdyby byly jednotlivé leaky nezávislé
OFB
- Output FeedBack
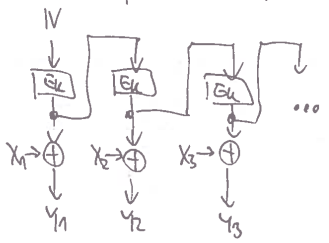
- také proudová šifra
- zajímavé vlastnosti:
- nemá žádný random access
- bit-flip v udělá akorát bit-flip v
- je permutace – když má moc malé cykly, stream je periodický s malou periodou a jsme v loji
Padding Oracle Attack
ukážeme pro CTR s paddingem 2. typu (celý padding je konstanta P určující velikost paddingu)
- dá se triviálně pozměnit a použít s CBC
podívejme se na poslední blok:
- předpokládejme
- budeme zkoušet všechny kombinace bit flips v posledním bajtu
- zpráva přijata poslední bajt změněného paddingu je
01- jelikož víme, které bit flipy vedou na
01a CTR používá jenXOR, jednoduše zjistíme původní hodnotu
- jelikož víme, které bit flipy vedou na
- pak změníme všechny padding bloky na a flipujeme bity v posledním bytu plaintextu, než je zpráva přijata (tím získáme původní hodnotu posledního bajtu plaintextu)
- poslední bajt plaintextu přidáme k paddingu, inkrementujeme a pokračujeme pro další bajty
- pokud
- všechny bit-flipy v předposledním bajtu zprávy vedou na korektní padding
- předpokládejme
Další zajímavé blokové šifry z finále AES
Serpent
- 128b bloky, 128-256b klíč, 32 iterací SPN + lineární transformace
- velmi konzervativní, veeeelmi pomalé
Twofish
- 128b bloky, 256b klíč, 16 iterací feistelovské sítě
- S-boxy jsou vypočítávány z klíče
- pomalá inicializace, měnění klíče je velmi časové náročné
Proudové šifry
- historicky populární – je jednoduché je implementovat na hardwaru
- známe jich ale docela málo
- nejde na ně použít Padding Oracle Attack
LFSR
- Linear-Feedback Shift Registers
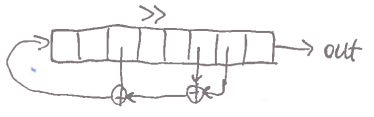
- bitshiftujeme, než vyjedeme z registru ven do outputu
- po každém shiftu vy
XORujeme všechny bity a výsledek přidáme na konec registru - problém: prvních bitů, které vyjdou z registru, je iniciální stav registru
- z dalších bitů sestavíme lineární rovnice pro klíč
- pro maximální periodu je soustava vždy regulární 💀
- z dalších bitů sestavíme lineární rovnice pro klíč
eSTREAM project
evropský projekt hledající nové proudové šifry
2004–2008
Profile 2 (HW) – 3 šifry
- požadován security level
- Trivium
Profile 1 (SW) – 4 šifry
- security level ještě větší než pro HW
- Salsa20
- z té se pak vyvinula ChaCha20 (dnes nejpoužívanější proudová šifra)
RC4
stav je klíčem vygenerovaná permutace pole
- indexy a
krok:
-
- – prohodím prvky na pozicích a
- output:
init:
- 256 kroků
- k navíc přičítám -tý znak klíče (opět modulo 256)
ChaCha20
následovník Salsa20
20 rund (odtud ChaCha20)
256b klíč, 64b počítadlo bloku, 64b nonce (různé verze mohou mít různá rozdělení bitů)
stav je zakódován do matice pomocí 32bitových čísel
init:

řádek – human-readable konstanty
a 3. řádek – klíč
řádek – počítadlo a nonce
runda:
- ARX šifra – runda je kombinace sčítání, XORů a rotací
- velmi dobře implementovatelné softwarově
- ARX šifra – runda je kombinace sčítání, XORů a rotací
výsledek po 20 rundách je vy
XORován s počátečním stavem- každá runda je invertibilní funkce, bez vy
XORování je velmi jednoduché získat klíč
- každá runda je invertibilní funkce, bez vy
Hashovací funkce
- v ideálním světě dokonale náhodná, jelikož je ale funkce deterministická, toto vůbec dělat nejde
požadavky na hashovací fci:
- nelze efektivně hledat kolize
- nelze efektivně hledat a taková, že
- nelze k danému obrazu najít nějaký jiný vzor
- pokud víme, že , pak neumíme najít takové, že
- nelze funkci jednoduše invertovat
- pro nějaké nelze najít takové, že
- nelze efektivně hledat kolize
pozorování:
Merkle–Damgårdova konstrukce
kompresní funkce
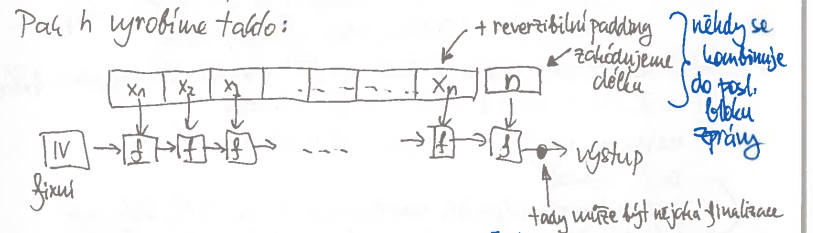
- udržujeme si nějaký stav, který pokaždé proženeme kompresní funkci dohromady s blokem kódovaného textu
konstrukce se může lišit mezi implementacemi
téměř nikdy se délka nepřidává jako samostatný blok, spíše se přidává do paddingu
vnitřní stav může být větší než blok – konstrukce je pak asymetrická
Věta: pokud je bezkolizní, je bezkolizní
předpokládejme, že jsme našli kolizi dvou různých vstupů v , pak máme 2 případy:
- kolizní vstupy mají stejný počet bloků
- v posledním kroku jsme ke dvoum stavům přihešovávali stejnou délku
- buďto byly stavy různé a našli jsme kolizi, nebo byly stavy stejné
- pokud byly stavy stejné, ale bloky různé, našli jsme kolizi, v opačném případě musel být předchozí stav stejný
- atd. atd… až na začátek, kde jsme buďto našli kolizi, nebo byly vstupy stejné, což je ale ve sporu s předpokladem, že jsou vstupy různé
- kolizní vstupy nemají stejný počet bloků
- v posledním kroku jsme k různým stavům přihešovávali různou délku
- tím jsme nutně museli najít kolizi v kompresní funkci
- kolizní vstupy mají stejný počet bloků
pokud bychom na konci nepřihešovávali , důkaz by nefungoval
Length extension attack
- někdo nám dal hash zprávy, ale né samotnou zprávu
- z totoho hashe můžeme vyrobit validní hash odlišné zprávy , která je extension původní zprávy
- pokud bychom na konci nepřihešovávali , stačilo by na konec přidat námi zvolené bloky a zahešovat je s původní
- pokud uživatel kontroluje hash dostatečně stupidně, dá se udělat length-extension i s přihashovaným
Collision attack
s řádově vstupy dokážeme s rozumnou pravděpodobností najít kolizi
- tím ale potřebujeme i paměti (a to jako seženu kde??)
lze s konstantní pamětí se stejnou časovou složitostí
zvolíme náhodnou první -bitovou zprávu , pak
- nekonečná posloupnost -bitových zpráv
budeme hledat hodnotu, která se v posloupnosti opakuje
grafový pohled: vrcholy jsou -bitové zprávy, hrany představují aplikování
každý vrchol má jedinou výstupní hranu
tento graf je konečný, ale my produkujeme nekonečnou posloupnost, nutně se tedy někdy musíme zacyklit – „lollypop graph”
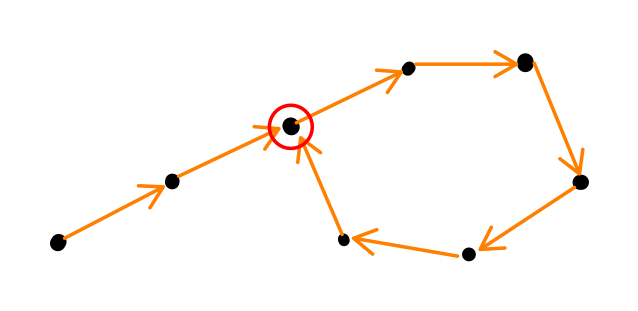
snažíme se najít spoj cyklu (červeně vyznačený vrchol) a oba jeho předchůdce (hledaná kolize)
celý graf je na paměť samozřejmě moc velký
- trik s dvěma běžci různých rychlostí:
- – v každém kroku projde 1 hranu
- – v každém kroku projde 2 hrany
- běžci se po nějaké době nutně potkají a stane se tak někde na cyklu
- nyní zastavíme a pustíme do grafu od začátku další
- tito běžci se opět po nějaké době potkají
- první fáze ( + ) trvala kroků – je na pozici , je na pozici
- v druhé fázi ( + ) za dalších kroků je na pozici , kdežto na pozici
- to je stejná pozice, jako ta, na které jsme skončili první fázi, čili běžci se museli potkat
- běžci se mohli potkat už dřív a první setkání nutně muselo proběhnout ve spoji cyklu
- trik s dvěma běžci různých rychlostí:
Multi-Collisions
můžeme jeden vstup zahashovat více funkcemi a výsledky konkatenovat
pokud ale alespoň jedna funkce je Merkle-Damgårdovského typu, výsledná síla není o moc větší
– výsledek pojmenujeme
– výsledek pojmenujeme
- stačí najít kolizí kompresní funkce, abychom našli kolidujících zpráv
- všechny možné kombinace / se totiž zobrazí na stejný hash
- na těchto zprávách pak jdou najít kolize ostatních ne M-D funkcí
tento problém je známý jen pro collision-resistance, pro invertibility-resistence je konkatenace docela fajn řešení
Parametrizované zprávy
chceme někomu dát podepsat dokument, který se jemu zdá být dobrý, ale my pak podpis přeneseme na naši zprávu, která má stejný hash
předchozím útokem najdeme pravděpodobně jen kolizní zprávu, která je nějaký hrozný garbage a nedává smysl
připravíme si pro kusy zprávy 2 sémanticky ekvivalentní ale textově odlišné varianty
- odlišných míst, nám dává možných variant zprávy
- zde už je docela slušná šance, že mezi nimi bude kolize
Innocent/Evil messages
- máme 2 množiny zpráv – innocent a evil
- chceme mezi nimi najít dvojici takovou, že se zahashují na stejný hash
- pomocí parametrizace vyrobíme innocent a evil zpráv
- problém: alespoň jednu z těchto množin si musíme udržovat v paměti
- můžeme vyrobit jiné množství innocent/evil zpráv a pamatovat si menší množinu za cenu horšího
- problém: alespoň jednu z těchto množin si musíme udržovat v paměti
Daviesova-Meyerova konstrukce
- konstrukce kompresní funkce z blokové šifry
- předpokládejme, že velikost bloku je stejná jako velikost klíče =
- zašifrované s klíčem
- pozor! i mohou být kontrolovány útočníkem
- zašifrované s klíčem
Esencialita xorování
- pokud bychom nexorovali:
- , tedy
- najdeme kolizi
- jakékoliv,
- hledání kolizí je pak velmi jednoduché
Proč nepoužívat s DES
DES je komplementární
- hupsík dupsík
- opět triviální na hledání kolizí
Merkle Trees
- rozdělíme data do bloků a zahashujeme každý blok
- bloky konkatenujeme do větších bloků a zahashujeme
- iterujem ke kořeni
- dobrý způsob, jak na dálku verifikovat velké objemy dat
- pošleme jen list a cestu ke kořeni
- používáno interně gitem
- problémky:
- neumíme rozlišit hash podstromu od hashe kořene
- útočník může tvrdit, že nějaký vnitřní vrchol je ve skutečnosti list
- jiná sekvence, která se zahashuje do stejného kořene, whoopsie daisyyy
- řešení: požadujeme fixní hloubku stromu a u každého vrcholu si poznamenáme, jestli je to kořen nebo list
Sakura
- basically Merkelovy stromy, akorát se SHA
Používané hashovací funkce
MD5
- Rivest 1992
- Message Digest
- Merkel-Damgårdova typu
- 128b výstup
- ve dnešní době už docela malé
- od roku 2004 už umíme produkovat kolize dost rychle (cca za 10 sekund na běžném laptopu)
- nikdy nikdo ale nenašel způsob, jak MD5 invertovat
SHA-1
NSA 1995
- nikdo NSA moc nevěří, ale po mnoho let to bylo to nejlepší, co jsme měli
160b výstup
od roku 2017 už umíme produkovat kolize, ale je to dost drahé
Merkel-Damgårdova typu s Davies-Mayerovskou kompresní funkcí
- kompresní funkce pochází z blokové šifry SHACAL
SHA-2 family
- NSA
- 224b až 512b výstup
- už docela reasonable security level, ale může být docela pomalá
- aktuálně nejpopulárnější s 256 b
- podobné SHA-1, ale udržuje si daleko větší vnitřní stav a má daleko více rund
- nikdo zatím (snad) nenašel způsob, jak ji rozbít
SHA-3
- vznikla jako výstup soutěže od NIST v roce 2015
- funguje na úplně jiném principu než ostatní funkce
- „houbová funkce”
Sponge construction
2 fáze – „nasávací” a „vymačkávací”
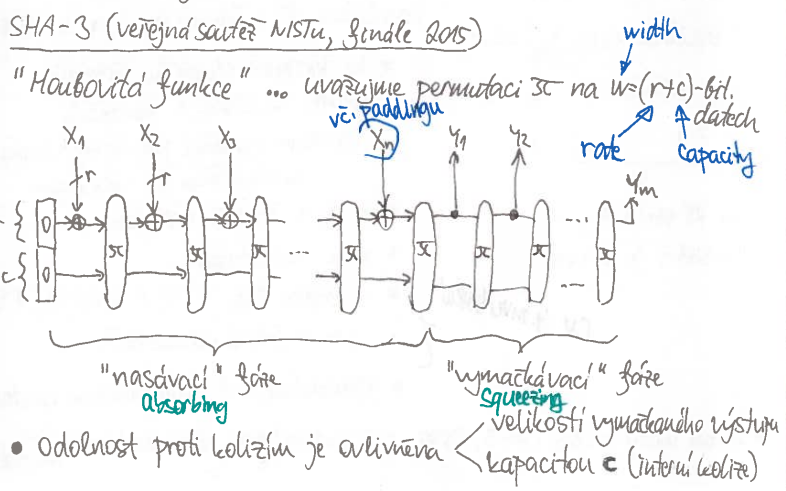
nasávací fáze
horní část stavu ( bitů) se vždy xoruje s bity vstupních dat
dolní část stavu se zachovává
zamícháme horní a dolní stav permutační funkcí
- poslední blok má nějaký padding
vymačkávací fáze
horní část stavu odešleme jako část výstupu
dolní část stavu se zachovává
zamícháme horní a dolní stav permutační funkcí
permutační funkce na bitech
- označme -tý horní stav jako a dolní jako
- – rate
- čim vyšší, tim rychlejší
- – kapacita
- pokud je moc malá, můžeme zaútočit na vnitřní stav
- jako vstup budeme používat samé nuly
- po řádově krocích bude některý dolní stav stejný jako jiný (pro )
- vnitřní kolizi budeme chtít zneužít pro hledání kolizních zpráv
- message A = ( nulových bloků) – stav
- message B = ( nulových bloků a pak xor a ) – stav
- security level je nejvýše
- pokud je moc malá, můžeme zaútočit na vnitřní stav
Keccak permutation
1600 bitů (damn, toje dost 👀)
SHA3-224
- chceme security level 224 použijeme (a tedy )
- potřebujeme jen 224 bitů výsledku, stačí použít výstup z poslední rundy nasávací fáze
SHA3-512
- ,
XOF
extendable output functions
- vymačkávají output asi donekonečna
- vlastně pseudonáhodné generátory parametrizované nějakým seedem
SHAKE-128
SHAKE-256
Message Authentication Codes
- zkráceně MAC
- funkce a
- – message, – key, – signature
- cílem útočníka je nechat podepsat špatnou zprávu stejným klíčem, jako by byla podepsána dobrá zpráva
Způsoby implementace
- hash konkatenace klíče se zprávou
- pokud je hashovací funkce založená na Merkle–Damgårdově konstrukci, lze snadno rozbít
- útočník přidá na konec plaintextu nějaký padding a extension
- pokud útočník zná stav na konci , pak jednoduše zjistí stav na konci
- nevim jak ale whatever
- funguje s SHA3 – standardizované pod jménem KMAC
- I am fucking lost
- taky prej docela bezpečný?
HMAC
- kde a pro nějaké konstanty a
- idea: máme nějaké dvě komponenty
- vnitřní komponenta musí být bezkolizní (nemusí být imunní vůči extension útoky)
- vnější komponenta pracuje s konstantně velkými vstupy – imunní vůči extension útoky
Kombinování šifer a MAC
Encrypt and MAC
- šifrování a vytvoření MAC probíhá nezávisle na sobě
- pošleme konkatenaci
- information leak: 2 stejné zprávy budou mít stejný MAC
MAC then encrypt
- podepíšeme plaintext a zašifrujeme konkatenaci plaintextu s podpisem
- je daleko těžší ovlivnit input šifrovací funkce
- skoro všechny implementace vedou na útoky padding orákulem
- pokud použijeme blokovou šifru, mezi MAC a šifrovací funkcí je skrytá vrstva přidávající padding na konec podepsané zprávy
- vezmeme nějakou zprávu, rozšifrujeme ji, odstraníme nějaký padding a ověříme MAC
- čas strávený ověřováním MACu závisí na tom, kolik paddingu jsme odstranili
Encrypt then MAC
- zašifrujeme plaintext a podepíšeme výsledek
- pokud útočník jakkoliv změní zašifrovanou zprávu, je ihned zastaven MACem
Konstrukce MAC bez hashovací funkce
CBC-MAC
CBC mód blokové šifry
- první blok je vyxorován s IV
- každý další blok plaintxtu je xorován předchozím blokem zašifrovaného textu
- jako output využijeme poslední blok zašifrovaného textu
IV musí být zahardkóděný v protokolu
- útočník může změnit bit v prvním bloku plaintextu a odpovídající bit v IV a máme kolizi
pokud leakne nějaký vnitřní stav
- útočník zkrátí zprávu a bude tvrdit, že tento leaknutý vnitřní stav je podpis
- pokud leakuje vnitřních stavů více, můžeme poslepovat několik zpráv dohromady se správnými podpisy – reassemble attack
- to btw znamená, že bychom nikdy neměli poslat zprávu, která je prefixem jiné zprávy (oof)
- fix: na začátek zprávy připojíme její délku
bezpečná proti chosen-plaintext útokům za předpokladu, že bloková šifra je ideální
Shannonovsky bezpečný MAC
- předpokládáme one-time klíč
- rodina 2-nezávislých hashovacích funkcí (takové ty klasické hashovací funkce z ADS1)
- zdrojová množina , cílová množina
- zprávy a podpisy
pokud známe validní dvojici zprávy a podpisu nám nepomůže s paděláním podpisů jiných zpráv
z libovolné dvojice zprávy a podpisu nelze dobře zjistit, jestli je to validní pár
- z definice podmíněné pravděpodobnosti (a definice 2-nezávislého systému, viz níže):
Hashovací funkce
- naše definice rodiny 2-nezávislých hashovacích funkcí
- česky: pravděpodobnost, že náhodná funkce z zobrazí nějaké zvolené na a jiné zvolené na je stejná jako pro perfektně náhodnout funkci
Př.: Lineární funkce
- splňují naši definici 2-nezávislých hashovacích funkcí
-
- takováto velikost klíčů je potřeba – klíč musí být alespoň 2krát delší než zpráva
- soustava lineárních rovnic pro a má jednozančné řešení
Polynomiální MAC
- trochu horší, než Shannonovsky bezpečný MAC, ale můžeme si dovolit daleko menší velikost klíče
- pro konečné těleso
- zpráva:
- one-time klíč: dvojice
- evaluace v lineárním čase – daleko rychlejší než Shannonovsky bezpečný MAC
- pokud ale známe validní dvojici klíče a zprávy, dává nám to informaci pro padělání podpisů (né ale nijak extra velkou)
GCM
Galois/Counter Mode
AEAD – Authenticated Encryption with Additional Data
dovoluje nám přidat k podpisu další data
nejčastěji se přidávají kontextová data protokolu
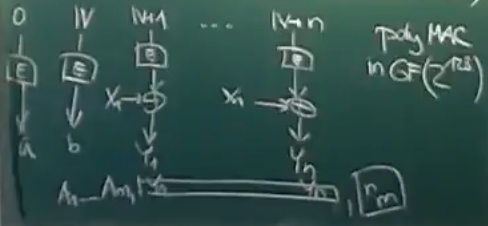
tohle v tý zkoušce prostě nebude, já to vzdávam
parametr můžeme dát fixní v poly MACu a jen generovat uniformně náhodné
Poly 1305
- aktuálně populární s ChaCha20
- velmi optimalizované pro dnešní HW
Náhodné generátory
- požadavky:
- útočník ani se znalostí předchozího výstupu neumí efektivně předpovídat budoucí výstup
- statistická rovnoměrnost
- (útočník by také neměl umět výstup ovlivnit)
- útočník ani se znalostí předchozího výstupu neumí efektivně předpovídat budoucí výstup
Možná řešení
- PRNG – pseudo-random number generator
- např. AES v CTR módu
- statisticky ok, pokud není vstupní posloupnost moc dlouhá
- stačí po nějaké době vygenerovat klíč pro AES znova
- např. AES v CTR módu
- physical randomness
- rádiový šum
- útočník může přijít a poslouchat ten samý noise, co já používám pro generování
- šum na rezistoru/diodě – termální
- útočník může generátor výrazně zchladit nebo zahřát a nechat tak ADCčko generovat dlouhé monotónní stringy
- actually se to děje docela často (imagine polít platební kartu tekutým dusíkem)
- radioaktivní zářič
- měření intervalů mezi zachycenými vyzářenými -částicemi
- uhhh, tenhle generátor asi nebude úplně nejčastější 💀
- video hash
- snímání lávové lampy (cloudflare moment)
- když vypnu světlo v místnosti tak dostanu samý nuly (lol)
- kruhový oscilátor
- útočník může měnit napětí na zdroji tak, aby napětí oscilovalo stejně, jako kruhový oscilátor
- timing kláves/disku/sítě
- budeme timing měřit velmi veelmi přesně a jako výstup brát nejnižší bity výsledku
- měření sítě – útočník může měřit taky
- rádiový šum
- kombinace obojího
- a samostatně nefungují moc spolehlivě
/dev/randoma spol.- kombinace několika fyzických zdrojů + PRNG na základě ChaCha20
RDRAND– nestabilní oscilátor procesoru- pokud by se někdo pokusil ovlivnit, procesor by to pravděpodobně poznal a na něčem kolosálně umřel
- velmi příhodné místo, kam dát do procesoru backdoor
Problémy
- jak se vzpamatovat z kompromitovaného stavu?
- entropy pooling – sbíráme entropii nějakou delší dobu a přimícháváme ji do generátoru najednou
- počet bitů by měl být roven alespoň security levelu, kterého chceme dosáhnout
- odhadování entropie – těžce těžký problém
- entropy pooling – sbíráme entropii nějakou delší dobu a přimícháváme ji do generátoru najednou
- jak iniciovat po bootu?
- čekání na sesbírání dostatku entropie – uhh, to bude trvat moc dlouho
- ukládání mezi booty – rollback do předchozího stavu znamená použití stejného poolu vícekrát (au)
- zálohy, snapshoty, nebo jen rychlé zapnutí, vypnutí a znovu zapnutí počítače
Fortuna
- Ferguson, Schneier – 2003
- několik komponent
Generátor
- AES se 128b počítadlem
- každé číslo počítadla šifrujeme tajným klíčem
- přegenerováváme po blocích, ale neresetujeme počítadlo
- neresetování počítadla nám pomáhá nezacyklit se
- přegenerováváme po blocích, ale neresetujeme počítadlo
Akumulátor
sbírá entropii z mnoha míst do 32 entropy poolů
- každý vzorek přidává -tý vzorek do
jakmile naakumuluje dost vzorků (ale né častěji než jednou za 100 ms), přihashuje jeho obsah ke klíči generátoru a v -tém kroku ještě všechny pro
- použité pooly vyprázdním
z kompromitovaného stavu se po čase sami vzpamatujeme:

Bezpěčný kanál (symetrický)
- Alice a Bob mají unikátní tajný klíč (pro každý kanál jiný)
- zkombinujeme (v každém směru):
- symetrické šifrování (třeba AES/CTR)
- MAC (konkrétně encrypt then MAC)
- sekvenční číslo 32b
- čili po zprávách chceme měnit klíče
- KDF – Key Derivation Function
- hashovací funkce z hlavního klíče
Algoritmická teorie čísel
složitost aritmetiky
- pro -bitová čísla
| Operace | Složitost |
|---|---|
| (lze v , ale s obří konstantou) | |
| a | |
GCD: Euklidův algoritmus
- modulící implementace
- v každé iteraci se alespoň jedno z čísel zkrátí o 1 bit
- iterací čas
- chytřejší implementace se dokážou dostat na čas
- značení:
- a jsou nesoudělná (znak )
Bézoutovy koeficienty
- lze je získat rozšířením modulící implementace Euklidova algoritmu (extended GCD)
- návod v KSP kuchařkách
Počítání modulo
- komutativní okruh – skoro těleso, akorát nemusíme nutně mít multiplikativní inverzi
Věta: má multiplikativní inverzi
- multiplikativní grupa – vybereme z okruhu jen prvky s multiplikativní inverzí
- uzavřená na násobení a každý prvek má multiplikativní inverzi
- multiplikativní grupa – vybereme z okruhu jen prvky s multiplikativní inverzí
pokud je prvočíslo, multiplikativní inverzi má vše je těleso
Důkaz:
- pro které existuje takové, že ?
- ekvivalentní s otázkou, zde rozdíl a 1 je nějaký -násobek
- pokud , máme triviální řešení pomocí Bézoutových koeficientů
- vlastně se ptáme, jestli existuje lineární kombinace prvků a taková, že je rovna
- jeden z těchto koeficientů je multiplikativní inverze
- pokud , tvrdíme, že multiplikativní inverze neexistuje
- označme
- i jsou dělitelné , tudíž i je dělitelné a jejich rozdíl je taktéž dělitelný
- protože se rozdíl rovná 1, musela by být 1 dělitelná , což je ve sporu s předpoklady
Malá Fermatova věta
- pokud , pak
- díky tomu
Eulerova věta
- zobecnění Malé Fermatovy věty
Věta: mějme , pak pokud , pak
Důkaz:
Lagrangeova věta: Je-li konečná grupa a je podgrupa , pak dělí
- podgrupa je podmnožina grupy uzavřená na všechny stejné operace
- nám stačí pro komutativní grupy
mějme a posloupnost
posloupnost se bude muset nutně začít opakovat, mějme tedy jako první opakující se 1
proč se první opakuje jednička:
pokud by se rovnala nějakému prvku různému od jedničky, pak by musela existovat dřívější repetice
podposloupnost je podgrupa (říkejme jí třeba )
- je uzavřená na násobení
dle Lagrange dělí
protože a , pak dělí
pokud bychom pokračovali s posloupností , dostaneme posloupnost zopakovanou několikrát za sebou
Teorie čísel
- okruh (skoro těleso, akorát nemusíme nutně mít multiplikativní inverzi)
- pokud je prvočíslo, pak máme těleso
- multiplikativní grupa
Čínská zbytková věta (CRT)
- mějme funkci takovou, že
- je periodická s periodou
- pokud definujeme , pak
- je periodická s periodou
Věta: mějme navzájem nesoudělné a , pak
Důkaz 1
je injektivní
- pokud , pak a
- musí tedy platit
je surjektivní
- je injektivní funkce mezi dvěma množinami stejné kardinality
je bijektivní
Důkaz 2
chceme
chceme najít a takové, že ,
proč nám a stačí?
jak najít
- , pro
- pokud , a můžeme skončit
- jinak si všimneme, že , tedy musí
- tedy
pro symetricky
Výpočet
- , kde
- pozorování pro prvočíselné :
-
- víme z definice tělesa
- ptáme se, kolik čísel od z není soudělné s
- to je to samé, jako se ptát na nesoudělnost s
- každé -té číslo je dělitelné a žádné jiné není
- ptáme se, kolik čísel od z není soudělné s
- pro máme
- lze vidět z CRT
- zvolíme
- pro číslo platí, že
- v obrazu máme řádkových indexů nesoudělných s a sloupcových indexů nesoudělných s (z definice)
- počet splňujících dvojic v obrazu je a jelikož je bijekce, pak je tento počet roven počtu splňujících dvojic v předobrazu
- umíme spočítat, pokud umíme rozdělit na prvočinitele
Faktorizace
- nikdo nezná polynomiální algoritmus
- známe sub-exponenciální algoritmy
- roste rychleji, než kterýkoliv polynom, ale pomaleji, než kterákoliv exponenciála
- např.
- polynomiální algoritmy na kvantových počítačích
- nikdo nebyl schopen (zatím) nikdy implementovat
- konstanty algoritmu jsou nepříjemně vysoké
Testy prvočíselnosti
- pravděpodobnostní testy
- deterministické polynomiální algoritmy (ale exponent je asi 6 💀)
Fermatův test
chceme zjistit, jestli je prvočíslo
pro spočítáme
- pokud , odpovíme „složené číslo,” jinak odpovíme „prvočíslo”
- test nemá false-negatives, ale může mít false-positives
- pokud , odpovíme „složené číslo,” jinak odpovíme „prvočíslo”
případy, ve kterých odpovíme, že máme složené číslo:
Eulerův svědek: takové, že
- Eulerových svědků je pro jedno číslo generally dost málo
Fermatův svědek: takové, že a
Carmichaelova čísla
- složená, ale vždy projdou Fermatovým testem
- nemají žádné Fermatovy svědky, mají jen Eulerovy svědky
- je jich naštěstí dost málo (ale stále nekonečně mnoho)
Pravděpodobnost
pokud je složené a není Carmichaelovo číslo
– množina všech nesvědků
- je podgrupa , tedy dle Lagrangeovy věty dělí
- dokonce je ostře menší, protože není Carmichaelovo
- je podgrupa , tedy dle Lagrangeovy věty dělí
pravděpodobnost false-positive
- stačí Fermatův test iterovat mnohokrát
Rabin-Millerův test
- odhalí i Carmichaelova čísla
vybereme náhodně
pokud , je složené – Eulerův svědek
spočítáme
- pokud výsledek není 1, je složené – Fermatův svědek
spočítáme
spočítáme
spočítáme
…
dokud není exponent lichý
- pokud někdy dostaneme výsledek , máme složené číslo – Riemannův svědek
- pokud někdy dostaneme výsledek , našli jsme prvočíslo
- pokud je , pokračujeme
Správnost
- algoritmus nedává false-negatives
- uvažme posloupnost
- každý prvek je odmocnina předchozího prvku
- pokud je některý prvek posloupnosti , pak následující prvek je
- pokud je prvočíslo, pak je těleso a máme nejvýše 2 možné hodnoty odmocniny a jsou to hodnoty a
- pokud tedy někdy v průběhu narazíme na hodnotu různou od , jistě není prvočíslo
- pokud je některý prvek posloupnosti , nemůžeme pokračovat
Věta Rabin:
- pravděpodobnost false-positive
Věta Miller:
- rozšířená Riemannova hypotéza
- pro složené svědek
Generování velkých prvočísel
chceme uniformně generovat náhodné -bitové prvočíslo (nepočítáme leading zeros)
náhodně tipujeme bity a testujeme
- v nejhorším případě tento přístup nikdy neterminuje
hustota prvočísel kolem je cca
- cca čísel v našem zvoleném intervalu jsou prvočísla
- protože je exponenciální vůči , pak pro nějakou konstantu
- to nám nějak docela stačí
Diskrétní logaritmus
Věta: je cyklická grupa (pro prvočíselné )
tedy
isomorfismus – v jednom směru umocňování, v druhém směru diskrétní logaritmus
jak ověřit, zda je generátor?
nemůžeme projít celou grupu, ta je na to moc velká :(
pokud není generátor
- mějme první opakování jedničky (taky se předtím nikdy nic neopakuje)
- je nějaká podgrupa
- uzavřená na násobení
- také platí, že (protože není generátor)
- dle Lagrange:
- pokud by byl generátor, pak takové neexistuje, protože první exponent, pro který bychom dostali jedničku, by byl
zrychlení: stačí projít všechny prvočíselné dělitele
- pro neprvočíselné s prvočíselným dělitelem máme:
pokud je generátor, je taky generátor?
- to se stane jen tehdy, když
- počet generátorů je , což je docela dost, takže náhodné vybírání a testování docela funguje
Diskrétní odmocniny
Modulo prvočíslo
- mějme , vyřešme
- pozorování: (pro )
- 1, 4 mají 2 odmocniny
- 2, 3 nemají žádnou odmocninu
- 0 má právě jednu (výjimka)
- počet odmocnin je vždy
- počet odmocnin je vždy sudé číslo (až na 0)
Kvadratické zbytky
čísla s přesně dvěma odmocninama
čísla se sudým diskrétním logaritmem jsou vždy kvadratické zbytky
- je odmocnina a jelikož počet odmocnin je vždy sudé číslo, máme kvadratický zbytek
čísla s lichým diskrétním logaritmem nikdy nejsou kvadratické zbytky
- nezbyly nám žádné odmocniny :(
Eulerovo kritérium
- algoritmus na zjišťování, zda má číslo kvadratický zbytek
Věta: je QR
Důkaz:
-
Důsledek:
- znaménko výsledku nám řekne, jestli je QR
Modulo složené číslo
- použijeme CRT na dělitelích
- pro jednoduchost předpokládejme, že pro prvočíselné
- dle CRT
- odmocniny můžeme počítat modulo prvočíselnými děliteli
- pro různých prvočíselných dělitelů máme různých odmocnin nebo žádné (bez důkazu)
- pokud umíme faktorizovat , umíme spočítat odmocniny
- nikdo neví, jak tohoto docílit bez rozkladu na prvočinitele
RSA
- Rivest, Shamir, Adleman – 1978
Klíč
velká prvočísla a
- ve dnešní době je potřeba alespoň 4tis.-bitová velikost prvočísel
modulus:
- , protože
- můžeme poměrně bezpečně posílat, protože je dost těžké velká čísla faktorizovat
šifrovací exponent:
dešifrovací exponent:
šifrovací klíč:
dešifrovací klíč:
jeden klíč nejde zjistit z druhého (nebo alespoň ne rozumně rychle)
Šifrování
zprávy jsou
Korektnost
musí platit
- pokud by , pak by z vypadlo jedno z prvočísel nebo
- třetí ekvivalence:
- pátá ekvivalence: Malá Fermatova věta
Efektivita
- polynomiální, ale pomalé
- často stavíme hybridní šifru z RSA a nějaké symetrické šifry
Zrychlovací triky
- veřejný klíč:
- volím malý (třeba 3 nebo 7)
- privátní klíč:
- pokud vytvářím klíče, mohu si zapamatovat a a dešifrovat pomocí CRT (čínské zbytkové věty)
- aritmetika je stejná, jako aritmetika a následně
- počítáme s menšími čísly → rychlejší
- pokud vytvářím klíče, mohu si zapamatovat a a dešifrovat pomocí CRT (čínské zbytkové věty)
Důležité vlastnosti
- komutativní:
- klíče musí mít stejný
- pozn.: mít několik klíčů se stejným není bezpečné, a tak se komutativita spíše nevyužívá
- homomorfní:
- vlastnost, která většinou spíše pomáhá útočníkům
Slepé podpisy
- Bob:
- má plaintext
- vybere – blinding factor
- pošle Alici
- pokud je i náhodné, pak je také náhodné
- Alice:
- umocní šifrovanou zprávu svým : a pošle Bobovi
- nikdy tak nezjistí nic o
- Bob:
Útoky
Špatná volba parametrů
- pokud , pak stačí spočítat odmocninu v , což je polynomiální
- známe-li , můžeme faktorizovat:
pokud , pak lze spočítat z
- malý si můžeme dovolit jen veřejný exponent
známe-li i , můžeme spočítat a máme stejný problém jako výše
Meet in the middle attack
mějme
- známe a zašifrovaný text , snažíme se dostat zprávu
- budeme hledat malá a taková, že
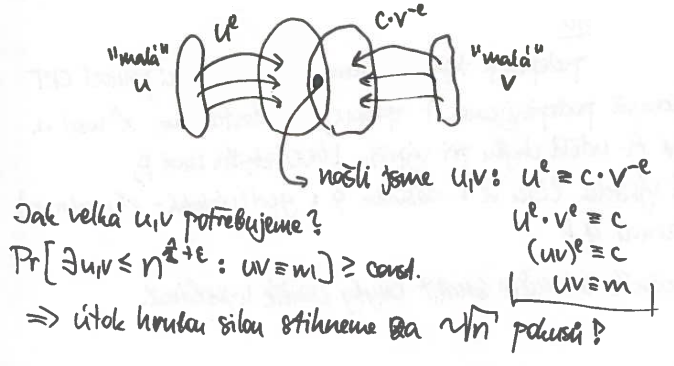
Podobné zprávy
-
- a
- pokud známe , a :
- je společný kořen polynomů a
- to je kořen
- s velkou pravděpodobností je tento polynom lineární
- to je kořen
- je společný kořen polynomů a
Podobná prvočísla a
- mohu zkoušet různá a zkoušet umocňovat , dokud to nevyjde
Několik klíčů se stejným
- každý majitel privátního klíče může faktorizovat
- při posílání téže zprávy více příjemcům lze jednoduše dešifrovat
Tatáž zpráva zašifrována klíči s různými
- např.: klíče , ,
-
- pomocí CRT:
- to znamená, že – hupsík dupsík
- pomocí CRT:
Chyba při výpočtu
- Alice podepisuje tajným klíčem s optimalizací pomocí CRT
- opakovaně podepisuje 1 zprávu , dostáváme
- pokud Alice udělá při některém z výpočtů chybu ve výpočtu zbytku modulo
- místo dostane
- – hupsík dupsík
- pravděpodobnost, že se toto reálně stane, je velmi nízká, ale útočník může chybu uměle vyvolat (už zase poléváme platební karty tekutým dusíkem…)
- jak se bránit: výsledek si někde vedle vymodulíme 64b prvočíslem
- pokud se stala chyba v původním výpočtu, v tomto výpočtu bude pravděpodobně taky (chyba by zmizela jen tehdy, kdyby bylo dělitelné tímto prvočíslem)
- v daleko menším čísle se ověřuje správnost výpočtu jednodušeji
RSA leaks
Legenderův symbol: – není to zlomek, tohle je prostě notace
pro prvočíselné a
- z Eulerova kritéria:
- Legenderův symbol je zobrazení
- homomorfismus
Jacobiho symbol:
pro liché složené a
Jacobiho symbol je zobrazení
- opět homomorfní –
- Jacobiho symbol je 0 tehdy, když jeden z dílčích faktorů je 0, což je tehdy, když je dělitelné jedním z faktorů , což je tehdy, když
Leak Jacobiho symbolu
jediný známý leak
- první rovnost platí z homomorfismu
- druhá rovnost platí, jelikož je Jacobiho symbol a je liché
- plaintext a zašifrovaný text mají stejný Jacobiho symbol!
- existuje polynomiální algoritmus na počítání Jacobiho symbolu, který nepotřebuje faktorizovat (pomocí nějaký cursed Gaussovy věty)
tento leak nám dává přesně 1 bit informace
Sémantická bezpečnost RSA
- žádná vlastnost plaintextu nemá jít efektivně zjistit z cyphertextu
Věta: pokud máme orákulum pro nebo pro , pak umíme dešifrovat v
Orákulum pro half
pro
první bit za desetinnou čárkou
- říká nám, jestli
druhý bit za desetinnou čárkou
- homomorfismus RSA →
můžeme iterovat
- každá iterace nás přibližuje blíže k reálné hodnotě
- po krocích máme aproximaci
- zaokrouhlení nám dá
Orákulum pro parity
pomocí orákula pro umíme simulovat orákulum pro :
homomorfismus RSA →
ve které půlce zjistíme z LSb
- samotné je sudé, ale počítáme
pokud :
pokud :
- , což musí být liché číslo
Padding Schemes
- RSA je kompletně deterministické, porovnáváním šifrovaných textů tak můžeme porovnávat i plaintexty
- chceme tedy zprávy předtím nějak randomizovat
PKCS#1 v1.5
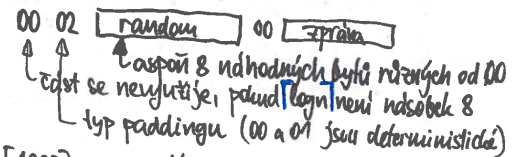
Bleichenbacherův útok
- pokud máme padding orákulum
- řekne, zda má dešifrovaná zpráva správný formát paddingu
- po několika milionech zpráv, které analyzujeme, dovedeme z v1.5 získat tajný klíč
PKCS#1 v2.0
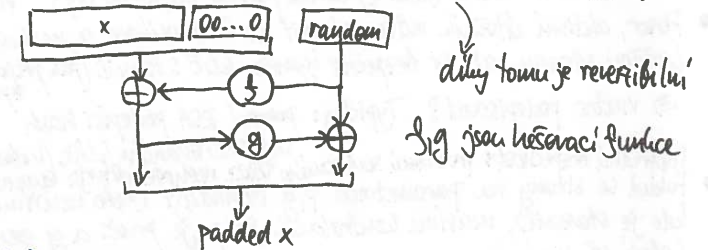
- vlastně 2-rundová Feistelova síť
- jednoduše reversovatelné
- oproti v1.5 nemá žádnou viditelnou strukturu, jako páry 00
- odolné vůči všem typům Bleichenbacherových útoků
Diffie-Hellman
protokol pro tajnou výměnu klíčů
základ ve složitosti diskrétního logaritmu
forward security
- pokud leakne privátní klíč podepisovací funkce, staré zprávy stále nejdou dešifrovat
Veřejné parametry: prvočíslo a generátor multiplikativní grupy
Alice: vygeneruje a pošle Bobovi
Bob: vygeneruje a pošle Alici
- oba umí spočítat
- pokud by někdo uměl spočítat diskrétní logaritmus v rozumném čase, DH by byl rozbitý
- DH má možná jiné zranitelnosti, o kterých nikdo neví
Útoky na DH
Man-in-the-middle attack
- stačí na obě dvě strany předstírat, že jsme druhá strana
- jelikož je veřejné, stačí vygenerovat pro každou stranu jedno a
- řešení: zprávu asymetricky podepíšeme
Útok na veřejné parametry
- některé implementace začínají dohodou na parametrech
- manipulace
- útočník může za dosadit mocninu generující podgrupu , která je dostatečně malá
- spočítání diskrétního logaritmu je pak snažší
- řešení: validování parametrů
Man-in-the-middle na veřejných parametrech
- pokud víme, že generuje podgrupu , která je dostatečně malá
- když Alice posílá , přepošleme Bobovi
- řešení: podepsání transkriptu protokolu
- transkript – seznam akcí, které se během protokolu staly
Information leak
- z lze poznat lichost (podobně i lichost )
- z toho lze získat paritu a tedy zjistit, jestli je kvadratický zbytek (QR)
Podgrupy
má alespoň 2 podgrupy: a kvadratické zbytky (QR)
mohutnost kterékoliv podgrupy dělí (Lagrange)
- pokud je prvočíslo, pak už žádné jiné podgrupy neexistují
- toto je tzv. „safe prime”
místo generátoru můžeme použít a generovat jen QR
- tím se dokonce vyhneme information leaku
Jak se vyhnout velkým exponentům
- nechceme pracovat s moc velkými exponenty, ale zachovat protokol bezpečným
- , kde má cca 256 b, daleko více
- pracujeme v podgrupě s generátorem , která má prvků
- DH zůstává stále stejně těžké
Sémantická bezpečnost
- zjistit nejnižší bit je stejně těžké jako zjstit všechno – podobně jako u RSA
ElGamalův kryptosystém
použití DH pro asymetrické šifrování založené na diskrétním logaritmu
nelze použít na asymetrické podepisování – veřejný klíč lze jednoduše získat z veřejných parametrů
veřejné parametry: prvočíslo a generátor grupy
privátní dešifrovací klíč:
veřejný šifrovací klíč:
šifrování:
- rovnoměrně náhodný prvek grupy
- posíláme dvojici a
dešifrování:
podobně jako RSA leakuje jestli je QR
- stačí opět vybírat zprávy jen z množiny QR
Eliptické křivky
dobrý zdroj malých grup s těžkým diskrétním logaritmem a žádnými malými podgrupami
- počítání bývá také docela rychlé
problém diskrétního logaritmu na eliptických křivkách bývá těžší, než běžně
- pokud bychom rozbili DH právě na rychlém počítání dl, eliptické křivky by to nejspíš ustály
nad reálnými čísly:
křivka = množina všech takových, že
- (kde jsou parametry takové, že )
- tato podmínka zaručuje právě 3 průsečíky s osou (jinak je křivka singulární)
- (kde jsou parametry takové, že )
např.:
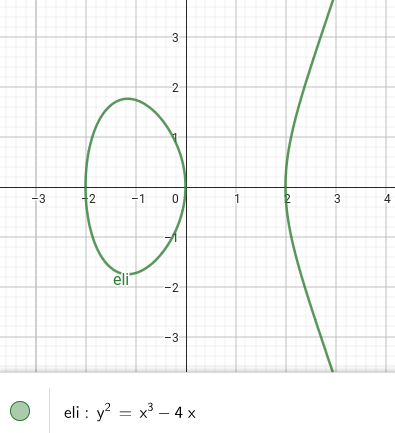
z bodů na křivce uděláme grupu s operací a neutrálním prvkem – „point at infinity”
jak vypadá pro a :
- :
- uvážíme přímku , která křivku protne ve 3 bodech – , a
- za výsledek prohlásíme zrcadlový obraz bodu podle osy
- vlastně to znamená, že kdykoliv jsou 3 body , a na společné přímce, pak
- a : výsledek je
- a :
- vezmeme tečnu v bodě
- eli. křivka má jen jeden další průsečík , odsud postupujeme stejně jako v 1. bodě
- :
toto je abelovská grupa
totéž lze dělat nad konečným tělesem
- opět vzniká abelovská grupa
také funguje nad jakýmkoliv konečným tělesem
- buďto pro nebo pro , kde
Asymetrické podpisy
- privátní podepisovací klíč a veřejný ověřovací klíč
- podepisovací a oveřovací funkce
- ověřovací funkce dostane na vstupu plaintext a podpis a musí říct, jestli tento podpis patří k původnímu plaintextu
- podepisovací funkce bývá randomizovaná, oveřovací funkce musí být tedy docela komplexní
Útoky
cíle útočníka:
- zjištění tajného klíče
- existenční padělání – schopnost podepsat zprávu, kterou jsme nikdy neviděli
- cílené padělání – schopnost podepsat předem určenou zprávu
k dispozici máme/můžeme mít:
- veřejný klíč
- known plaintext – útočník zachycuje zprávy s podpisy
- chosen plaintext – útočník nechává podepisovat vybrané texty
- většinou se snaží dostat podpis k jiné zprávě, než předložil k podepsání
RSA podpis
- tajný encryption key, veřejný decription key,
Existenční padělání
jen na základě veřejného klíče
vyberu si úplně náhodný podpis a pošlu
pravděpodobně nesmyslná zpráva
Cílené padělání
- chosen plaintext
- můžeme použít slepé podepisování
- řešení: nebudeme podepisovat samotnou zprávu, ale hash zprávy
- tím se zbavujeme homomorfismu RSA
ElGamalův podpis
- velmi různý od ElGamal šifry
- funkce nebude vyžadována na zkoušce (thank fucking god)
DSA
digital signature algorithm
ECDSA – DSA s eliptickými křivkami
NIKDY!!!! nepoužívat stejná čísla na šifrování
- z dvou zpráv zašifrovaných stejným číslem lze lehce získat privátní klíč (whoopsie daisyy)
Kryptografické protokoly
typicky
- výměna nonces
- A generuje master secret
- A posílá m.s. B zašifrované veřejným klíčem B
- A a B podepisují transkript protokolu jejich tajnými klíči
- použijeme KDF pro vytvoření symetrických klíčů z m.s.
- průběh komunikace pomocí symetrické šifry a MAC
- po nějakém čase přegenerováváme symetrické klíče pomocí KDF
2, 3 většinou pomocí DH
Implementační pasti
- fuzzing
- používání C (nebo jiného low-level jazyka)
- šahnu si někam do paměti, kam nemam :(
- nepoužívání C
- jednoduché exploitnout
Side channels
Remote attacker
- timing attack
- např. dotaz na heslo – porovnáváme 2 stringy po znacích
- porovnávání 2 stringů se stejným prefixem bude trvat déle – můžeme měřit
- ambiguous data
- nějaký script se dá schovat např. do komentáře, který se podle různé implementace parserů vykoná nebo ne
- JSON má hned několik standardů ( 😭 )
- XML – má velmi komplexní standard, takže snad žádná implementace parserů není správná
- UTF-8 a Unicode
- format detection
- některý Java bytecode je validní jpeg (pardon??)
- nějaký script se dá schovat např. do komentáře, který se podle různé implementace parserů vykoná nebo ne
- DOS
- zaplavení serveru s nesmyslnými requesty
In the same room
- měření power consumption
- některé instrukce procesoru jsou jinak náročné
- elektromagentický šum
- měření
- sound-based keylogger
- měření teploty/„ošoupanosti” kláves/tlačítek
Physical access
- coldboot attack
- náš běící stroj má nahrané klíče v RAMce… tak ji prostě vytahnem a rychle strčíme k nám
- Trojan horse
- prostě si nahraju na stroj svůj backdoor
Run my code
stačí mít na stránce javascript, hehe
Meltdown
- právě zažívám meltdown a mým procesorem to nebude 😭
Cache-based AES attack
chosen plaintext
- existuje verze (daleko komplikovanější), která funguje i s known plaintextem
AES má 128b klíč a 10 rund (poslední je ✨speciální✨)
dřív se na AES používal „výbornej” zrychlovací trýček
stav AES je uložen v tabulce

první 3 kroky rundy se dají vyměnit za kombinaci několika lookupů v tabulkách
vezmu 4 bajty , , a na hlavní diagonále stavu
konkrétně jsou to lookupy , , a
- jsou nějaké předpočítané 256b tabulky dávající 32b výstup = 4B
- poslední spešl runda používá jen jinej typ tabulek
XORtěchto lookupů má 4B, ze kterých postavíme první sloupec výsledku- pro další sloupce jen vezmeme prvky na 1., 2. … vedlejší diagonále (plus cyklicky doplníme)
běžné L1 cache dnešních počítačů mají 64B bloky
- každý blok obsahuje 16 buněk tabulky
chosen plaintext: zafixuji , , a a zbytek bloku volím naprosto náhodně
- AES je deterministický – zafixované parametry se vždy zacachují na stejné místo
- po několika pokusech je jednodušší měřením rychlosti přístupu zjistit, jak vypadají předpočítané tabulky (teda dozvíme se vždy jen vrchní 4 bity každého bajtu kvůli splitování do nloků cache)
neorzumim tomu, prostě nevim… tak se omlouvám, že je tahle část pěkně trash
ale klidně vám popovídám něco o meltdownu :3
Udržování tajemství
- na disku fakt ne pls
- RAM
- když dojde, začne swapovat věci na disk (hups)
- když crashne, vyhodí core dump
- registry
- mohou skončit v paměti
Hesla
- nejpoužívanější způsob zabezpečení
- většinou ale nejslabší článek celého systému
- lidi jsou trochu dementi
Uchovávání hesel
- hashování hesel
- většinou server-side
Předpočítávání hashů hesel
pokud bychom chtěli crackovat hesla, mohli bychom si předem předpočítat úplně všechny hashe všech možných hesel z univerza a pak jen lookupovat
- to je ale strašně drahý na paměť
chytřejší předpočítávání
- samplovací funkce z hashe vybere náhodné heslo z univerza všech možných hesel
graph LR
password1 -- h --> hash -- sampling function --> password2
- iterováním tohoto procesu stavím řetízky
graph LR
p1 --> p2 --> p3 --> mid:::hidden --> pn
předpočítám si všechny řetízky pokrývající celé univrzum hesel
- pro každý řetízek si pamatuji první a poslední heslo v řetízku
když chceme cracknout heslo, zahashováním se dostaneme na nějakou pozici doprostřed řetízku
doiterujeme se na konec, odtamtud skočíme na začátek a dojdeme zpět k našemu vstupnímu bodu do řetízku
nyní už ale známe předka tohoto bodu, což je hledané heslo
tradeof horšího času za méně paměti
- pokud je délka řetízku , pak máme paměť a čas , ne?
- pozor! řetízky se často spojují, ve skutečnosti tak spotřebujeme paměti daleko více
- pokud je délka řetízku , pak máme paměť a čas , ne?
Rainbow tables
- pro každou hranu řetízku použijeme jinou samplovací funkci – máme jiné barvy hran
- to komplikuje lookup hesla – když crackujeme, nevíme, kam jsme se zahashovali a tedy jakou samplovací funkci máme použít, abychom pokračovali v našem řetízku
- jednoduše tedy vyzkoušíme všech možností
- to komplikuje lookup hesla – když crackujeme, nevíme, kam jsme se zahashovali a tedy jakou samplovací funkci máme použít, abychom pokračovali v našem řetízku
- pokud by měly 2 řetízky zkolidovat, pravděpodobně se potkají na hranách jiné bary
- řetízky se nespojí
- nyní máme čas a paměť opravdu cca

Ochrana proti brute-force útokům
salting
- hashuje se konkatenace hesla a soli – nějaký random string
- obrana proti rainbow-tables
- také není vidět, že 2 uživatelé mají stejné heslo
iterování hashovací funkce
- zpomaluje hashování, čímž ale zpomaluje i brute-force útoky
PBKDF2
password-based key derivation function
odvozená z libovolné pseudonáhodné funkce s klíčem (typicky HMAC)
vstup: salt a délka požadovaného hesla
výstup:
konstrukce :
Challenge-response autentikace
sequenceDiagram
participant c as client
participant s as server
c ->> s: login
s ->> c: nonce, salt
c ->> s: HMAC( h( passwd || salt ), nonce )
note right of c: znalost HMAC podpisu nám nepomůže v získávání hashe hesla
note right of c: podpis závisí na nonci, imunní vůči replay útokům
- server si musí pamatovat hash hesla se solí
- pokud ze serveru získáme hash, můžeme předstírat, že jsme klient a provést ten samý protokol
SCRAM
salted challenge-response authentification mechanism
- řešení případu, kdy ukradneme přímo hash hesla ze serveru
setup: vybereme salt a počet iterací
- zahashujeme heslo:
- vyrobíme client key:
- vyrobíme server key
- server si pamatuje salt, klíč serveru a hash klíče klienta
- klient si nepotřebuje pamatovat nic krom svého klíče
průběh:
sequenceDiagram
participant c as client
participant s as server
c ->> s: login a client-nonce
s ->> c: salt, server-nonce, #iterací
c ->> s: client-proof
note right of c: client-proof = Kc XOR HMAC( h(Kc), transkript )
s ->> c : server-proof
note left of s: server-proof = HMAC( Ks, transkript )
note left of s: nepovinné (myslim)
klient umí jednoduše verifikovat server proof
server si na moment zjistí klientův klíč a pak ho zahodí
- server má a pak samotný hash klíče a samotný transkript
- je inverzní sám k sobě, takže lze zjistit jednoduše
poměrně těžké zamezit timing side-channel attacks
DNSSEC
- secure domain naming system
- DNS – strom doménových jmen
Záznamy
- ve vrcholech doménového stromu
- A, AAAA, MX, …
- delegace subdomén – NS záznamy
- na zónách, nikoliv doménách (trochu rozdíl?)
Ta jakože security část
veřejný klíč domény – uchováván v DNSKEY záznamu
tajným klíčem podepisujeme záznamy – RRSIG záznamy
- podpis je generován pro dvojici jméno + záznam
DS záznamy v „otcovských” doménách
- hash veřejného klíče domény
- jako každý záznam je podepsán otcovskou doménou
změna klíčů
- při změně klíčů máme u domény 2 klíče najednou
- update klíče by znamenalo updatovat celou větev (au)
- řešení: 2 klíče – key signing key a zone signing key
TODO: tady chybí docela velká část o PKI a chain-KDF (a už se mi nechce ji dopisovat, sry)
TLS
transport layer security
- nástupce SSL – secure sockets layer
- SSL 1 → SSL 2 → SSL 3 → TLS 1.0 → TLS 1.1 → TLS 1.2 → TLS 1.3
stream protokol
autentikace, zabezpečení, integrita
používán jako mezivrstva většiny internetových protokolů
HTTPS = HTTP přes TLS
DTLS – datagram TLS (varianta vhodná např. pro použití s UDP)
TLS 1.3
- výměnna klíčů
- typicky Diffie-Hellman na eliptických křivkách
- autentikace
- RSA podpis + certifikát
- šifrování
- předchozí verze šly často rozbít padding orákulem
- AEAD – Authenticated Encryption with Additional Data
- buďto AES v Galois/Counter módu, nebo třeba ChaCha20 + Poly1305
- dohoda na parametrech
- ve verzi 1.3 poměrně omezená – nechceme volit slabé parametry
- můžeme zvolit verzi TLS, grupu pro DH ze seznamu, autentikační mechanismus, šifru ze seznamu
Record protokol
stará se o šifrování a MAC
přidává padding
- takto můžeme přidat více paddingu, než je potřeba, abychom zamezili leakování informací v naší používané šifře
podprotokoly
- handshake
- posílání aplikačních dat
- alert
- posílá se, když se něco pokazí
- také se pošle speciální alert, když chceme ukončit komunikaci
Key schedule
- TLS má několik podčástí, které všechny potřebují nějaké klíče
- založeno na HKDF
- extrakce a expanze – podobné houbovité konstrukci
- nejdříve extrahujeme nějakou kratší sekvenci, kterou následně expandujeme na tak dlouhou, jak potřebujeme
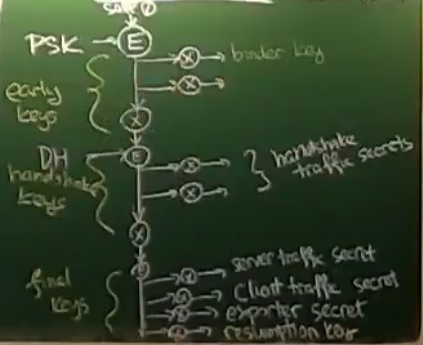
- TLS je nejčastěji používáno pro navázání spojení a vygenerování šifrovacího klíče pro toto spojení
- na to je ten předposlední klíč – exporter secret
Handshake
- před zvolením klíčů nepoužíváme žádné šifrování
sequenceDiagram
participant c as client
participant s as server
c ->> s: Client Hello
Note right of c: key share, nabízené parametry, nabídka PSK
s ->> c: Server Hello
Note left of s: key share, vybrané parametry, vybrané PSK
alt šifrovaná část
s ->> c: Certificate
s ->> c: (Cert Request)
Note left of s: někdy chceme i autentikaci klienta
s ->> c: Cert Verify
Note left of s: podpis dosavadních zpráv certifikovaným klíčem
s ->> c: Finished
s ->> c: Začíná posílat aplikační data
Note left of s: pokud nepotřebujeme autentikaci klienta
c ->> s: <br/><br/><br/> Certificate
c ->> s: Cert Verify
c ->> s: Finished
c ->> s: Začíná posílat aplikační data
end
- další možné zprávy
- ← New session key
- nonce a stav
- klient vyrobí z nonce a resumption key nový PSK (Pre-Security key)
- díky tomuto může server poslat několik noncí a klient může otevřít několik paralelních spojení najednou
- ←→ Key update
- můžeme změnit klíč, nebo požádat druhou stranu, aby změnila klíč
- ← Hello retry
- pokud klient pošle data, která se serveru nelíbí, může jej požádat o nový Client Hello
- ← New session key
Rozšíření
zero-latency handshake
- klient může poslat nějaké další early data
- následně může začít posílat svá data bez čekání na server
- jak ale tato data zabezpečit?
- typicky když obnovujeme ztracené spojení se serverem
- problém: útočník může zachytit client hello včetně early data a znovu jej poslat serveru, který si neukládá historii
- chceme používat jen s idempotentními akcemi (třeba get request), jinak nebezpečné
SNI – Server Name Indication
- jeden server může obsluhovat více domén
- v HTTP můžeme do hlavičky přidat jméno domény, na kterou se ptáme
- přes TLS složité – před výměnou dat musíme ověřit certifikát vázaný na doménové jméno a server zatím neví, na kterou doménu se dotazujeme
- do Client Hello přímo přidáme doménové jméno
- jeden server může obsluhovat více domén
ALPN – Application-Level Protocol Name
- pokud na stejném TCP portu běží více protokolů
- např. chceme na TCP běžet HTTP1 a HTTP2
- klient nabídne protokoly, server jeden vybere
- pokud na stejném TCP portu běží více protokolů
Encrypted Client Hello
- magie
Internet PKI
public key infrastructure
založeno na standardu ITU X.509
- přespříliš komplexní standard
- původně designováno OSI model
Motivace
máme hrozně moc CA
- donedavna pouze komerční, nově i non-profit (např. Let’s Encrypt)
intermediate certificates
- certifikáty pro ověřování certifikátů
- každý je používá jinak
- CA si každý rok vyrobí sama pro sebe nový interm. c. a podepisuje se jím
- delegování ověřování na jinou organizaci
- nemůžeme pak kontrolovat, kolika organizacím takto věříme
- generally to neni dobrej nápad
kdo je přesně svázán s certifikátem?
- podobná jména fake firem
- mnoho i legit firem má ofiko sídlo v daňových rájích a je těžké rozpoznat real firmu od sus firmy
Obsah certifikátu
- jméno držitele
- alternativní jména držitele
- hash veřejného klíče
- kdo certifikát podepsal + podpis
- použití
- platnost od do
- různá rozšíření
Zneplatňování certifikátů
CRL
- Certification Revocation List
- vydává CA
- po chvíli může být fakt velký
- také docela pomalé
Custom revocation list
- seznam velmi důležitých certifikátů udržovaný v prohlížeči
- např certifikáty jednotlivých CA
OCSP
- Onlice Certificate Status Protocol
- protokol, skrz který můžeme kontaktovat CA, jestli je certifikát platný
- problém: pokud útočník odchytí komunikaci, může request zahodit a nedozvíme se nic
- problém2: CA může tímto způsobem hezky monitorovat, které stránky navštěvujeme
OCSP Stapling
- na certifikáty se neptáme my, ale servery
- servery mohou odpovědi cachovat po nějakou krátkou dobu
- můžeme k certifikátu přidat požadavek, že chceme vždy OCSP staple
- moc se ale nepoužívá
Limited lifetime
- nastavíme lifetime dost krátký na to, aby to nevadilo
- např. měsíc
Certificate Transparency project
- mnoho logů
- každý log má seznam všech vydaných certifikátů
- Merkelův strom – těžké měnit historii, lehké přidat data na konec seznamu
- každá CA by měla poslat seznamy svých vydaných certifikátů několika CT logům
- pokud vlastníme doménu, můžeme monitorovat tyto logy
- pokud vidíme log pro naši doménu, který jsme si nevyžádali, vyhlásíme poplach
- historicky některé CA dělaly shady věci a byly tímto způsobem odhaleny
- je to sice jen taková záplata na tenhle zbastlenej certifikační systém, ale je to to nejlepší co máme