Přírodou inspirované algoritmy
Struktura těchto poznámek odpovídá seznamu požadavků ke zkoušce z webu docenta Martina Piláta z akademického roku 25/26. Konkrétní požadavky jsou následující:
Základy strojového učení
- vysvětlit rozdíly mezi jednotlivými typy strojového učení (učení s učitelem, bez učitele, zpětnovazební učení)
- vysvětlit rozdíly mezi jednotlivými úlohami strojového učení s učitelem (regrese, klasifikace)
- popsat typy příznaků (kategorické, ordinální, číselné) a jejich předzpracování (kódování kategorických a ordinálních příznaků, škálování číselných příznaků)
Zpětnovazební učení
- popsat problém zpětnovazebního učení intuitivně (agent, prostředí, hledání strategie)
- popsat prostředí jako Markovský rozhodovací proces
- definovat zpětnovazební učení jako problém hledání strategie maximalizující celkovou odměnu agenta
- definovat pojmy hodnota stavu a hodnota akce
- popsat základní myšlenku Monte-Carlo metod (v rozsahu podle textu na webu)
- vysvětlit Q-učení (včetně vzorce pro aktualizaci matice Q)
- popsat algoritmus SARSA
- vysvětlit, jak použít Q-učení v prostorech se spojitými stavy a akcemi
Jednoduchý genetický algoritmus
- popsat základní verzi evolučního algoritmu s binárním kódováním
- popsat základní genetické operátory (jednobodové, n-bodové křížení, mutace)
- popsat ruletovou a turnajovou selekci
- vysvětlit výhody a nevýhody turnajové a ruletové selekce
- vysvětlit, co je fitness funkce
- popsat elitismus
- popsat metody pro environmentální selekci (přenos jedinců do další populace), (μ,λ) a (μ+λ)
- popsat rozšíření jednoduchého GA na problémy s celočíselným kódováním
Evoluční algoritmy pro spojitou optimalizaci
- definovat problém spojité optimalizace
- popsat genetické operátory používané ve spojité optimalizaci - aritmetické křížení, zatížené a nezatížené mutace
- vysvětlit rozdíl mezi separabilními a neseparabilními funkcemi
- popsat algoritmus diferenciální evoluce a jeho výhody
Evoluční algoritmy pro kombinatorickou optimalizaci
- popsat mutace pro permutační kódování
- popsat křížení používaná při permutačním kódování (OX, PMX, ER)
- vysvětlit použití evolučních algoritmů pro problém obchodního cestujícího
Lineární a kartézské GP, gramatická evoluce
- popsat lineární genetické programování (kódování jedince, operátory)
- popsat kartézské genetické programování (kódování jedince, operátory)
- popsat gramatickou evoluci (kódování jedince, operátory)
- vysvětlit, jak řešit problém s příliš krátkým nebo dlouhým jedincem v gramatické evoluci
Stromové genetické programování
- popsat stromové genetické programování a jeho genetické operátory
- popsat práci s konstantami ve stromovém genetickém programování
- popsat typované genetické programování
- popsat automaticky definované funkce
- vysvětlit, jak u automaticky definovaných funkcí zabránit zacyklení/nekonečné rekurzi
- porovnat jednotlivé typy genetického programování a jejich výhody/nevýhody
Perceptronové neuronové sítě
- popsat, jakým způsobem počítá jeden perceptron
- popsat algoritmus pro trénování perceptronu a vysvětlit, kdy konverguje
- popsat strukturu vícevrstvých perceptronových sítí
- popsat aktivační funkce používané ve vícevrstvých perceptronech (sigmoida, tanh, ReLU)
- popsat metodu pro trénování neuronových sítí (backpropagation)
- odvodit pravidla pro adaptaci vah v metodě zpětného šíření (alespoň pro výstupní vrstvu + ideu pro skryté vrstvy)
RBF sítě
- popsat RBF jednotku a architekturu RBF sítě
- vysvětlit princip trénování RBF sítí
- popsat algoritmus k-means
- porovnat geometrické vlastnosti RBF sítí a vícevrstvých perceptronů
Konvoluční sítě
- popsat funkci konvolučního filtru
- popsat funkci pooling vrstev v konvoluční síti
- popsat architekturu konvoluční neuronové sítě
- vysvětlit, co jsou matoucí vzory a jak ovlivňují praktické nasazení neuronových sítí
- popsat algoritmus FGSM pro vytváření matoucích vzorů
- vysvětlit myšlenku přenosu uměleckého stylu
- vysvětlit základní fungovaní generative adversarial networks (podle rozsahu v textu na webu)
Rekurentní neuronové sítě
- definovat, co jsou rekurentní neuronové sítě
- vysvětlit, kde se rekurentní sítě používají
- vysvětlit trénování rekurentních sítí pomoci algoritmu zpětného šíření v čase
- vysvětlit problém s explodujícími a mizejícími gradienty
- popsat princip Echo State sítí
- popsat trénování Echo State sítí
- popsat LSTM buňku a architekturu LSTM sítě
- vysvětlit výhody Echo State sítí a LSMT sítí v porovnání se základními rekurentními sítěmi
Neuroevoluce
- popsat použití evolučních algoritmů pro trénování vah v neuronové síti
- popsat algoritmus NEAT - reprezentace jedince, operátory
- vysvětlit význam inovačních čísel v algoritmu NEAT
- popsat myšlenku algoritmu HyperNEAT
- popsat rozšíření algoritmu NEAT pro hledání architektur neuronových sítí (algoritmus coDeepNEAT)
- vysvětlit myšlenku algoritmu novelty search
- porovnat novelty search a evoluční algoritmy a diskutovat jejich výhody/nevýhody
Hluboké zpětnovazební učení
- vysvětlit algoritmus hlubokého Q-učení
- porovnat Q-učení a hluboké Q-učení
- popsat triky s experience replay a target network
- vysvětlit vliv experience replay a target network na hluboké Q-učení
- popsat algoritmus DDPG
- popsat actor-critic přístupy
- popsat advantage a zdůvodnit, proč se používá
- popsat metodu A3C
Particle Swarm Optimization
- popsat aktualizaci poloh a rychlostí v PSO
- popsat topologie používané v PSO (globální, geometrické, sociální)
- vysvětlit vliv topologií na algoritmus PSO
- vysvětlit použití PSO pro řešení problémů ve spojité optimalizaci
Ant Colony Optimization
- vysvětlit základní pojmy ACO - feromon, atraktivita
- popsat generování řešení pomocí ACO
- popsat aktualizaci feromonu na základě kvality nalezeného řešení
- popsat použití ACO pro řešení problému obchodního cestujícího a vehicle routing problému
Artificial Life
- vysvětlit rozdíly mezi jednotlivými typy umělého života (soft, hard, wet)
- vysvětlit rozdíly mezi silným a slabým umělým životem
- popsat 1D a 2D celulární automaty
- popsat pravidla Game of Life
- popsat pravidla Langtonova mravence
- vysvětlit pojem dálnice u Langtonova mravence
- popsat systém Tierra
- popsat jedince v systému Tierra
- vysvětlit způsob adresování (definování cílů skoku) v systému Tierra
- popsat příklady vytvořených jedinců v sytému Tierra (paraziti)
Základy strojového učení
- umělá inteligence se dá cca rozdělit na 2 části:
- Symbolická – symbolický popis světa ve formálním jazyce
- Výpočetní – učení se chování z dostupných dat a pozorování
Strojové učení a optimalizace
- hlavní 2 oblasti aplikace přírodou inspirovaných algoritmů
- typický cíl strojového učení:
- nastavení parametrů modelu tak, aby co nejlépe odpovídal dostupným datům
Rozdělení dle typu učení
- Učení s učitelem – zadané objekty a k nim příslušné výstupy
- cílem je najít model, který zadaným objektům přiřazuje správný výstup
- klasifikace – třídění objektů do kategorií
- regrese – přiřazování vstupním datům číselné hodnoty
- cílem je najít model, který zadaným objektům přiřazuje správný výstup
- Učení bez učitele – zadány objekty bez příslušných výstupů
- rozdělování dat do skupin (shlukování)
- naučit se, jak objekty vypadají, a následně generovat nové objekty (generativní modely)
- Zpětnovazební učení – naučit se chování v daném prostředí, aby co nejlépe řešil zadaný problém na základě zpětné vazby prostředí
- učíme se hrát hru tím, že zkoušíme různé akce a díváme se, jak ovlivňují skóre
Typy příznaků
- jednotlivé měřitelné vlastnosti dat
Kategorické – skupiny bez uspořádání (kvalitativní)
- barva, pohlaví, …
- předzpracování: binární vektor
- každý prvek má vektor určující do kterých kategorií spadá
Ordinální – skupiny s uspořádáním
- velikost oblečení, věkové skupiny, nejvyšší dosažené vzdělání, …
- předzpracování: číselná hodnota
- mám uspořádání, takže mohu použít jako labely
Číselné – kvantitativní
diskrétní – počet okvětních lístků, …
spojité – výška, teplota, váha, …
předzpracování – škálování
kdyby jedny data byly v rozmezí 0-1 a jiný v rozmezí 0-100000, model by z toho mohl být dost zmatenej
normalizace – naškáluju vše do fixního intervalu (typicky )
standardizace – naškáluju všechny data aby měly střední hodnotu 0 a směrodatnou odchylku 1 (tj. snažím se je přiblížit standardnímu normálnímu rozdělení)
Zpětnovazební učení
- agent se učí interakcí s prostředím
- cílem je maximalizovat celkovou (diskontovanou) odměnu
Základní pojmy a intuice
- agent a prostředí – agent pozoruje stav , provede akci , prostředí se změní na a agent obdrží odměnu
- strategie (): funkce přiřazující stavu pravděpodobnostní rozdělení nad akcemi
Proces hledání strategie
- Exploatace – agent vždy vybírá nejlepší známou akci pro daný stav
- může uvíznout v lokálním optimu
- Explorace – agent zkouší náhodné akce, aby prozkoumal stavový prostor
- nejspíš nebude dostávat moc dobré odměny
- -greedy – s pravděpodobností zvolí nejlepší akci, s pravděpodobností zvolí náhodnou
- kombinace explorace a exploatace
- velmi záleží na parametru
Markovské rozhodovací procesy (MDP)
Definice (Prostředí MDP): Čtveřice :
- – množina stavů
- – množina akcí
- – pravděpodobnost přechodu ze stavu do při akci
- Markovská – pravděpodobnost přechodu záleží pouze na a
- – funkce odměny za přechod
Hodnotové funkce
Hodnota stavu – očekávaný celkový zisk, pokud začneme ve stavu
Hodnota akce – očekávaný zisk, pokud ve stavu provedeme akci
střední hodnota odměny plus diskontovaná hodnota následujícího stavu
pomocí tohoto vzorce pak definujeme jako
Cílem agenta je najít optimální strategii maximalizující
Metody učení
Monte-Carlo
- agent hraje celé epizody až do konce
- hodnoty se aktualizují až při skončení epizody na základě skutečného výsledku
- Výhody:
- nevyžaduje Markovské prostředí
- zero-knowledge – nemusíme vůbec znát to jak prostředí vypadá
- dobré pro epizodické úkony s vysokou variancí – jeden tah v pokru nám nedá žádnou odměnu až do úplného konce hry
- Nevýhody:
- pomalá konvergence při velkém rozptylu odměn
- výpočetně náročná neefektivní pro velké stavové prostory
Temporal-Difference (TD)
aktualizace probíhá po každém kroku
vychází z Bellmanových rovnic:
- počítám nejen odměnu za aktuální stav, ale i co očekávám že dostanu v dalším stavu (vynásobeno diskontním faktorem)
Výhody:
- informace o odměně se propaguje zpětně z cílových stavů do předcházejících
Nevýhody:
- pokud je náš iniciální odhad špatný, pak updaty do budou také špatné
- propagation delay – informace o se propaguje v každém kroku jen o jeden krok nazpět
- v některých nedobrých podmínkách mohou hodnoty a divergovat do nekonečna
- konkrétně pokud se zkombinuje bootstrapping (TD), off-policy učení (Q-učení) a aproximace funkce (neuronky)
| Metoda | Monte Carlo (MC) | Temporal Difference (TD) |
|---|---|---|
| Bias | Žádný (používá reálné hodnoty) | Vysoký (používá jen odhady) |
| Rozptyl | Vysoký (náhoda velmi ovlivňuje výsledky) | Nízký (aktualizace jsou malé) |
| Rychlost učení | Pomalé (pro jednu aktualizaci musíme odehrát celou epizodu) | Rychlé (aktualizuje se po každém kroku) |
| Stabilita | Typicky stabilní | V nedobrém setupu může divergovat |
Q-učení
off-policy – aktualizace nezávisí na akci, kterou agent skutečně provedl, ale pouze na té, která by byla v daný moment optimální
learning rate ()
jak moc velkou váhu dáváme nové informaci
moc vysoký – hodnoty budou nekontrolovaně oscilovat a nikdy nezkonvergují
moc nízký – propagace nové informace bude moc pomalá a model se nebude učit
SARSA
- **on-policy **– aktualizace závisí na akci, kterou agent provedl
- pojmenováno podle posloupnosti , , , , ve vzorci (myslim)
- Výhody:
- update je jednodušší (ale moc to ten algoritmus nezrychluje)
- nachází dobrá řešení pro problémy s velkou penalizací za neúspěch
- Nevýhody:
- přehnaně opatrný – algoritmus se bude vyhýbat stavu, ze kterého se mohu snadno dostat do hrozně špatné situace, i když by ten stav byl normálně velmi dobrý
Problémy a spojité prostory
- velký stavový prostor – matice je obrovská a učení je pomalé
- spojité stavy/akce
- diskretizace: rozdělení spojitých hodnot do intervalů
- aproximace: použijeme neuronku k odhadu funkce
Multiagentní učení
- prostředí s několika jedinci:
- roboti ve skladu, vojáci v bitvě, …
- vysoká složitost – „společná” jedna akce je -tice akcí všech jedinců
- roste více méně exponenciálně
- credit assignment problem – jak rozdělit odměnu mezi více agentů?
- porovnám odměnu z prostředí s odměnou, kterou by agent dostal, kdyby nedělal nic
- tím řeším problém líného hráče, co by jinak dostával odměnu zneužíváním odměny ostatních hráčů
- porovnám odměnu z prostředí s odměnou, kterou by agent dostal, kdyby nedělal nic
Jednoduchý genetický algoritmus
Základní pojmy
- jedinec – vektor
- je fixní a stejné pro všechny jedince
- populace – množina jedinců v aktuální generaci
- fitness funkce – funkce měřící kvalitu jedince
- evoluční algoritmus se vždy snaží fitness maximalizovat
- **genetické operátory **– mechanismy měnící řešení (křížení/mutace)
Typické problémy řešené jednoduchým genetickým algoritmem
- OneMAX – fitness = počet jedniček ve vektoru
- taková blbůstka na ukázání že algoritmus funguje
- Součet podmnožiny – chceme najít podmnožinu se součtem
- **Problém batohu **– 1 pokud jsme vybrali předmět, 0 pokud ne
- triviální fitness funkce: fitness = součet cen prvků, jedincům kteří překročí kapacitu dáme fitness 0
- problém: hrozně špatní jedinci mají stejnou fitness jako jedinci co jsou velmi blízko dobrému řešení
- triviální fitness funkce: fitness = součet cen prvků, jedincům kteří překročí kapacitu dáme fitness 0
Algoritmus
- Náhodně vytvoř iniciální populaci , nastav
- dokud nejsme spokojení s výsledkem: 2. vyhodnoť fitness jedinců v 3. vyber množinu rodičů 4. vytvoř populaci potomků aplikováním genetických operátorů na 5. ,
Selekční mechanismy
Ruletová selekce – pravděpodobnost výběru jedince je přímo úměrná jeho fitness
- Výhody:
- intuitivní a přesná
- Nevýhody:
- přímo záleží na hodnotách fitness
- nefunguje pro zápornou fitness
- to bychom mohli vyřešit přičtením dostatečně velké konstanty ke všem , v ten moment se ale velké rozdíly mezi některými jedinci smažou a selekce se stane náhodnou (toho můžeme ale i využít pro zesílení/zeslabení vlivu selekce)
- Výhody:
Turnajová selekce – náhodně vybereme jedinců (typicky 2) a z nich vybereme s velkou pravděpodobností toho nejlepšího
typicky provádíme několik turnajů, do kterých vybíráme s nahrazením (with replacement)
Výhody:
záleží pouze na pořadí jedinců dle jejich fitness
funguje i pro záporné hodnoty
snadno se implementuje a paralelizuje
Nevýhody:
opět se trochu mažou rozdíly mezi některými jedinci, ale furt je to docela dobrý
není snadné ukázat že funguje dobře
Genetické operátory
Křížení
- cílem je zkombinovat dobré vlastnosti dvou rodičů
- jednobodové – vybere se náhodný bod, ve kterém se „rozřízne” vektor rodičů; potomek má první část od prvního rodiče a druhou od druhého
- -bodové – vybere se bodů; části rodičů se v potomkovi střídají
- uniformní – pro každý bit se náhodně rozhodně, od kterého rodiče bude pocházet
- čim více bodů křížení, tím větší diverzita je křížením vytvořena
Mutace
- zvyšuje diverzitu řešení – efektivní strategie proti padání do lokálních optim
- některé náhodné bity jsou flipnuty
- jakou mutaci použiju velmi záleží na problému, který řeším
- např. v problému batohu dává smysl náhodně zvolit jeden bit s hodnotou 1 a jeden s hodnotou 0 a flipnout je (tim prakticky vyhodím jeden předmět z batohu a nahradím jej jiným)
Enviromentální selekce (tvorba nové generace)
- Elitismus – malé množství nejlepších jedinců z předchozí generace se zkopíruje přímo do nové generace beze změn
- zabraňuje tomu, aby genetické operátory omylem nezničily dosud nejlepší nalezené řešení
- snižuje diverzitu – opravdu chceme jen malý elitismus, jinak se můžeme dostat do lokálního optima
- Notace evoluční strategie
- : Z rodičů se vygeneruje potomků
- nová generace se vybírá pouze z potomků ()
- : Nová generace se vybírá z rodičů i potomků dohromady
- přirozeně zahrnuje elitismus
- steady-state algoritmus: případ
- v každém kroku vytvoříme jen jednoho potomka
- extrémně stabilní
- : Z rodičů se vygeneruje potomků
Rozšíření do celočíselného kódování
někdy binární řetězec nestačí (např. indexy měst v problému obchodního cestujícího)
jedinec – vektor
genetické operátory:
- mutace – typicky přičtení/odečtení náhodné malé hodnoty nebo prohození dvou prvků
- křížení – většinou stejné jako u binárního
- musíme si dát pozor na zachování validity řešení (např. aby se v cestě obchodního cestujícího neobjevilo město dvakrát)
Evoluční algoritmy pro spojitou optimalizaci
Spojitá optimalizace
- chceme najít vektor takový, který minimalizuje (či maximalizuje) cílovou funkci při zachování určitých omezujících podmínek
- Využití: ladění parametrů strojů, hledání vah v neuronkách, …
Genetické operátory
Mutace
- u reálných čísel nestačí překlopit bit
Nezatížená (unbiased) – vygeneruje novou náhodnou hodnotu v povoleném rozsahu, bez ohledu na původní hodnotu
Zatížená (biased) – upravuje stávající hodnotu
nejčastěji gaussovská mutace – přičteme malé náhodné číslo z :
nejčastěji
Křížení
jde použít klasické -bodové křížení
Aritmetické křížení – lineární kombinace rodičů
- pro
- technicky vzato by mohl mít jeden jedinec více rodičů, ale to se asi spíš nepoužívá
Separabilita a podmíněnost funkcí
- při optimalizaci je zásadní, jak spolu jednotlivé proměnné souvisejí
Separabilní funkce – funkci lze optimalizovat po jednotlivých složkách nezávisle
diferenciální rovnice celé funkce jde nějak rozdělit na sadu diferenciálních rovnic menší dimenze
vrstevnice těchto funkcí jsou elipsy orientované rovnoběžně s osami souřadnic
Neseparabilní funkce – mezi proměnnými existuje závislost
- vrstevnice jsou elipsy co nejsou rovnoběžné s osami
- Podmíněnost (conditioning) – vyjadřuje „protaženost vrstevnic”
- vysoce podmíněná funkce vypadá jako úzké dlouhé údolí
- pokud algoritmus neumí měnit směr prohledávání, může se v takovém prostoru „houpat” velmi dlouho, než najde dobré řešení
Diferenciální evoluce (DE)
algoritmus navržený pro neseparabilní a vysoce podmíněné funkce
populace je množina vektorů
Diferenciální mutace:
pro každého jedince z populace vytvoříme mutanta :
vybereme tři náhodné jiné jedince
vypočítáme rozdíl mez dvěma z nich a přičteme ho ke třetímu:
- je scaling faktor (obvykle )
Křížení
- uniformní křížení mezi původním jedincem a mutancem
- vzniká zkušební jedinec (trial vector)
Selekce
- turnaj 1v1 – pokud je trial lepší než původní , nahradí jej v příští generaci
- Výhody:
- invariantnost vůči rotaci a škálování: mutace využívá rozdíly mezi skutečnými jedinci v populaci – nevadí neseparabilita ani vysoká podmíněnost
- samo-adaptivita: pokud je populace rozptýlená, mutace jsou velké; jakmile populace konverguje k optimu, rozdíli se zmenšují a mutace se zjemňují
- jednoduchost: minimum parametrů (velikost populace, a pravděpodobnost křížení)
Evoluční algoritmy pro kombinatorickou optimalizaci
- kombinatorická optimalizace hledá nejlepší uspořádání nebo výběr prvků z konečné množiny
- problém: standardní genetické operátory by často tvořily nevalidní jedince
Celočíselné kódování
např. pokud je cílem rozdělit prvků do podmnožin
- bin packing, barvení grafů, …
jedinec – vektor
- číslo na pozici říká, do které množiny patří -tý prvek
genetické operátory
- křížení – v podstatě stejné jako pro binární kódování
- mutace – na dané pozici změníme číslo na libovolné jiné, nebo přičteme/odečteme nějakou konstantu
Permutační kódování
příklady použití:
problém obchodního cestujícího
bin packing problem – vypermutuje biny aby se pak dala dobře použít first-fit heuristika
jedinec – vektor
- chceme, aby se každé číslo v jedinci objevilo právě jednou – permutace
Mutace
- mutace musí zachovat integritu permutace
- Swpa – náhodně se vezmou dvě pozice a jejich hodnoty se prohodí
- Insertion – náhodný prvek se vyjme a vloží na jinou náhodnou pozici
- oproti swapu se tím jeden úsek posune o 1 doleva a jinej o 1 doprava
- Inversion – vybere se náhodný úsek a ten se otočí pozpátku
- velmi efektivní mutace pro TSP
- Scramble – vybere se úsek a jeho prvky se náhodně zpermutují
Křížení
Order Crossover (OX) – chceme zachovat relativní pořadí rodičů
- rodič 1:
1 2 | 3 4 5 | 6 7 8 - rodič 2:
3 4 | 1 8 6 | 5 2 7
prohodíme prostřední části rodičů
_ _ | 1 8 6 | _ _ __ _ | 3 4 5 | _ _ _
zbývající pozice se doplní z původního rodiče tak, že se začne za druhým bodem křížení a následně se pokračuje od začátku
bereme pouze prvky, které v potomkovi ještě nejsou
4 5 | 1 8 6 | 7 2 38 6 | 3 4 5 | 2 7 1
- rodič 1:
Partially Mapped Crossover (PMX) – výměna segmentů a následné opravení
- rodič 1:
4 1 | 6 3 7 | 2 5 - rodič 2:
7 1 | 5 4 3 | 6 2
prohodíme prostřední části rodičů
4 1 | 5 4 3 | 2 57 1 | 6 3 7 | 6 2
prohozené dvojice v prostřední části udávají mapování, podle kterého opravíme duplicitní prvky
mapování:
7 1 | 5 4 3 | 2 64 1 | 6 3 7 | 5 2
- rodič 1:
Edge Recombination (ER) – když nám nezáleží na absolutní pozici, ale na sousedství
- speciálně navržený pro TSP a podobné
- pro každý prvek vypíšeme sousedy v permutaci z obou rodičů
- bereme i „wrap around” sousedství
- začne se náhodným prvkem (nejčastěji tím s nejméně sousedy)
- jako další prvek se vybere soused aktuálně vybraného prvku, který má sám nejméně ještě nepoužitých sousedů
- pokud někdy v procesu dojdou sousedé, vybere se náhodný prvek
Problém obchodního cestujícího (TSP)
- je zadán úplný graf s ohodnocenými hranami
- cílem je najít nejkratší Hamiltonovskou kružnici
Použití EA
- jedinec – permutace indexů vrcholů
- fitness funkce – např. převrácená hodnota celkové délky kružnice
- křížení – OX či PMX jsou ok, ale ER je nejlepší volba
- často se kombinuje s jinými heuristikami (2-approx, Christofides, …)
- narozdíl od heuristik ale nepožadujeme trojúhelníkovou nerovnost
Lineární a kartézské GP, gramatická evoluce
- klasické genetické algoritmy pracují s fixní velikostí jedince
Genetické programování
- vyvíjení programů pomocí evolučních algoritmů
- komplexnější struktury
Lineární genetické programování (LGP)
jedinec – posloupnost instrukcí (př. instrukce:
add F, D[I])- podobně jako v assembleru
- provádí se následně na simulovaném stroji s registry a paměťovým polem
mutace
- záměna jedné instrukce za jinou
- změna konstanty
- …
křížení
- může být více méně stejné jako -bodové křížení v binární reprezentaci
- můžeme ale měnit délku výsledného jedince – messy -point
Kartézské genetické programování (CGP)
program je orientovaný graf (typicky mřížka )
- každý vrchol reprezentuje funkci (např.
AND,OR,+,-, … )
- každý vrchol reprezentuje funkci (např.
jedinec – vektor genů, kde každý gen určuje:
- Funkci daného vrcholu
- Vstupní hrany z předchozích vrstev
více méně hradlová síť
samostatně jsou ještě kódovány indexy vrcholů, ze kterých se skládá konečný výstup programu
ne všechny vrcholy v mřížce musí být zapojeny do výsledného výstupu
mutace
- změna funkce vrcholu
- změna vstupů vrcholu
- výměna vrcholů ze kterých se skládá výstup
křížení – spíš se nepoužívá
Gramatická evoluce (GE)
- odděluje kódování jedince (genotyp) od výsledného programu (fenotyp)
- k definici jazyka programu se používá bezkontextová gramatika (BNF)
- jedinec – posloupnost celých čísel (kodonů)
- čísla v jedinci určují, které pravidlo z gramatiky se použije pro přepis aktuálního neterminálu
- výběr pravidla:
- mutace – standardní mutace na vektoru čísel
- křížení
- můžeme použít standardní křížení na vektoru čísel
- problém: pravidla nemusí dobře navazovat
- strukturální křížení – prohazují se celé podstromy odvození
- vybere se stejný neterminál v obou rodičích a prohodí se geny, které jej a jeho následníky definují
- můžeme použít standardní křížení na vektoru čísel
Problémky jedinců (a jejich řešení)
- příliš krátký jedinec – dojdou čísla v jedinci, ale v programu stále zbývají neterminály
- wrapping: pokud dorazíme na konec, začneme jedince znovu číst od začátku
- pokud gramatika obsahuje rekurzi a wrapping se opakuje mockrát, proces nemusí terminovat
- penalizace: jedinec s neúplným programem dostane velmi špatnou fitness
- wrapping: pokud dorazíme na konec, začneme jedince znovu číst od začátku
- příliš dlouhý jedinec – program skončil (máme pouze terminály), ale jedinec má stále nevyužitá čísla
- obvykle tolik nevadí, prostě jsme nevyužili všechen genetický materiál, který nám ale může posloužit jako zdroj biodiverzity v dalším křížení
Evoluce pravidel
klasifikace
jedinec – množina pravidel/znalostí
- např. pokud je vstupem vektor čísel, pravidla mohou být
- pokud pro -té číslo platí podmínka , pak objekt patří do třídy
- musíme řešit případy, kdy vstup splňuje podmínky pro více pravidel
- pravidlům můžeme přiřazovat váhy – pak nás zajímá jak moc jedinec podmínky splňuje
- např. pokud je vstupem vektor čísel, pravidla mohou být
mutace
- změna klasifikované třídy pro pravidlo
- výměna některé podmínky za jinou, její úplné vypuštění, nebo přidání
- změna váhy pravidla
křížení – může být stejné jako pro běžné evolučky
Stromové genetické programování
jedinec – program reprezentován jako strom
- terminály (listy) – vstupy nebo konstanty
- neterminály (vnitřní vrcholy) – funkce
křížení – výměna náhodných podstromů mezi dvěma rodiči
mutace
- bodová mutace – vymění terminál/neterminál za jiný
- podstromová – nahrazení podstromu náhodně vygenerovaným
počáteční populace – náhodné stromy s
- pevně danou hloubkou
- pevným počtem neterminálů
- nejčastěji se používá kombinace obojího (ramped half-and-half)
stromy mohou často v čase nekontrolovatelně růst bez zlepšení fitness
- můžeme dát penalizaci ve fitness funkci nebo zafixovat max. hloubku
Práce s konstantami
- nemůžeme mít v množině terminálů všechna možná reálná čísla
- Základní sada – do terminálů dáme jen pár čísel, program si musí ostatní hodnoty vypočítat sám
- Efemérní náhodné konstanty (ERC) – speciální terminál, který se při inicializaci změní na pevné náhodné číslo
Typované genetické programování (Strongly Typed GP)
- v základu předpokládáme, že každá funkce může vzít za vstup cokoliv
- neodpovídá realitě programování
- typy – každý terminál/vstup má přiřazený datový typ (to samé rozhraní funkcí)
- křížení a mutace jsou omezeny, aby zachovávaly typovou kompatibilitu
Automaticky definované funkce
program má možnost vytvořit si vlastní definice některých neterminálů
- modularizace a znovupoužitelnost kódu
jedna ADF je tak vlastně nějaký předdefinovaný podstrom, se kterým můžeme pracovat
- běžně se omezuje množina vstupů/neterminálů pro snazší prohledávání
problém: možnost nekonečného zacyklení, když se některé ADF odkazují na jiné
- hierarchie volání – funkce jsou očíslovány (ADF0, ADF1, …)
- ADF0 může volat jen terminály, ADF1 jen terminály a ADF0, …
- mohu vždy volat jenom terminály a funkce s nižším číslem
- hierarchie volání – funkce jsou očíslovány (ADF0, ADF1, …)
Perceptronové neuronové sítě
Perceptron
- matematický model biologického neuronu
- provádí 2 základní kroky:
Lineární aktivace () – vážený součet vstupů + bias
- bias ovlivňuje nakolik musí být vážený součet vetší než 0, aby se perceptron aktivoval
- často se bias zakóduje mezi váhy – přidáme vstup s konstantní hodnotou 1 a je jeho váha
Nelineární výstup – pokud , výstup je 1, jinak 0 (nebo -1, záleží na nás)
Trénování perceptronu
iterativní proces, který upravuje váhy na základě chyby
je potřeba mít v trénovací množině vstupní data napárovaná s příslušnými výstupy
- – learning rate
- – požadovaný výstup (ground truth)
- – výstup perceptronu
konvergence – trénování perceptronu zaručeně konverguje v konečném počtu kroků data jsou lineárně separabilní
Vícevrstvé perceptrony (MLP)
- neurony řadíme do vrstev
- zatím se budeme zabývat pouze dopřednými (feed-forward) sítěmi
- Vstupní vrstva – pouze předává data (příznaky )
- Skryté vrstvy – nelineární transformace dat
- umíme tím řešit i lineárně neseparabilní problémy
- vždy (lineární) aktivace + nelineární transformace
- Výstupní vrstva – produkuje výslednou odpověď
- různé funkce podle záměru: sigmoida, , ReLU, …
Aktivační funkce
- abychom mohli síť trénovat pomocí gradientů, potřebujeme diferencovatelné funkce
- logistická sigmoida:
- obor hodnot
- dříve standard, dnes méně častá kvůli mizejícímu gradientu
- pro s velkou absolutní hodnotou je gradient skoro 0
- hyperbolický tangens
- obor hodnot
- podobný sigmoidě, stejný problém s mizejícím gradientem
- ReLU (rectified linear unit):
- dnes nejpoužívanější
- výpočetně velmi jednoduchá, pomáhá v trénování hlubokých sítí
Gradienty a zpětná propagace
- Backpropagation – algoritmus pro efektivní výpočet gradientu chybové funkce vzhledem k vahám v síti
- např. derivace sigmoidy je
Dopředný chod – data projdou sítí, spočítá se výstup a celková chyba podle chybové funkce (nejčastěji MSE)
Zpětný chod – chyba se šíří od výstupu zpět
pomocí chain rule pro parciální derivace zjišťujeme, jak moc která váha přispěla k celkové chybě
aktualizujeme jednotlivé váhy takto:
Příklad
Setup
Věta (řetízkové pravidlo pro parciální derivace): Nechť a každá je funkce nezávislých proměnných . Parciální derivace vzhledem k je rovna:
- každá funkce může ofc záviset jen na některých proměnných z , jejich derivace podle takové proměnné je pak konstantní 0
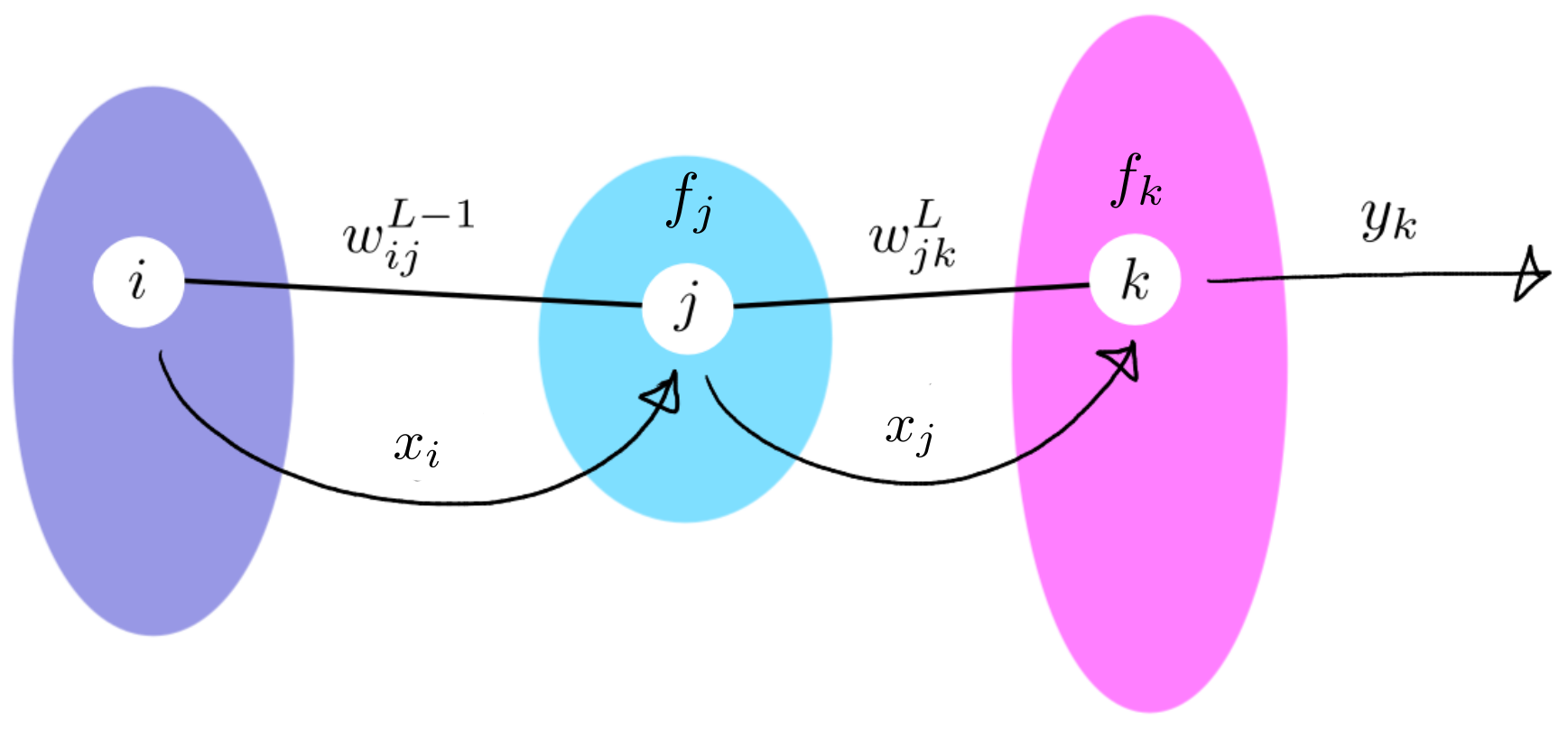
- je váha mezi -tým neuronem v poslední skryté vrstvě a -tým neuronem na výstupu, je váha mezi neurony a v předchozích vrstvách apod.
- výstup -tého výstupního neuronu je
- je výstup -tého neuronu v poslední skryté vrstvě
- stejně tak je výstup -tého neuronu ve vrstvě ještě předtím (prostě jako na obrázku, kdybych musela u každé proměnné říkat co je to za vrstvu, tak bych se asi zbláznila)
- podobně jako pro výstupní vrstvu také máme aktivace a pro
Výpočet pro výstupní vrstvu
nechť je očekávaný výstup -tého neuronu, předpokládáme že loss funkce je MSE: , její derivace je:
- v derivaci nemáme žádnou sumu, jelikož ovlivňuje pouze jeden jedinej output , který ovlivňuje jen jednu část
Výpočet pro předchozí vrstvy
pokud složíme aktivace a funkce, dostaneme, že poslední dvě vrstvy počítají výraz:
derivací chybové funkce dostaneme:
v prvním kroku jsme aplikovali chain rule podél , následně jsme aplikovali chain rule na , z čehož už jsme dostali členy nezávislé na
- zde se nám v derivaci už suma objevuje, protože váha sice ovlivňuje jen jeden skrytý neuron , ten ale ovlivňuje všechny další neurony na další vrstvě
první část sumy () jsme spočítali už při výpočtu pro výstupní vrstvu, označme ji tak , čímž dostáváme:
nikde jsme vlastně nepoužili informaci o tom, že značí výstupní vrstvu a můžeme tedy použít stejný výraz pro všechny skryté vrstvy, pokud ještě dodefinujeme
získali jsme tím znova známe adaptační pravidlo:
Více vzorů
- stochastický gradient descent – update vah pro každý vstupní vzor zvlášť
- výpočetně náročné, snadno se přetrénujeme na jedno dato
- batch learning – změna váhy je určená jednouduchým součtem derivací pro „batch” (pokud používáme loss funkci která je definovaná jako součet, což MSE je)
- běžne je batch celý dataset
- minibatch – updatujeme po menších částech datasetu (třeba po 32 nebo 64 vzorech)
RBF sítě
dopředná neuronová síť
RBF jednotka (neuron) – místo skalárního součinu počítá vzdálenost vstupu od svého středu
Aktivace:
– nějaká aktivační funkce (kernel)
často Gaussova funkce:
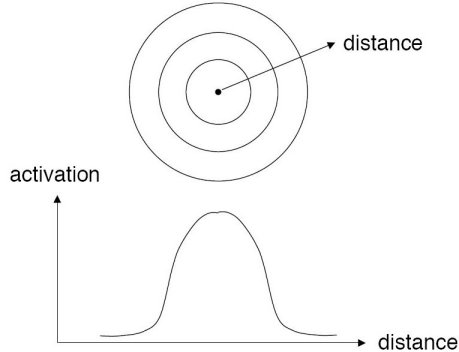
– nějaká norma (nejčastěji Euklidovská)
lokální – nejvyšší hodnota je když a se zvyšující se vzdáleností rychle klesá
typicky má pouze jednu skrytou vrstvu
celá síť tak počítá funkci:
- jsou váhy pro výstupní vrstvu (tady předpokládáme že výstupní neuron je jenom jeden, jinak máme matic vah )
Trénování
- jelikož máme málo vrstev, celé trénování probíhá ve 3 fázích
- mnohem rychlejší než zpětná propagace
Hledání středů (): najdeme ve vstupních datech shluky, středy těchto shluků se stanou středy RBF jednotek
- hledání shluků se dělá nejčastěji pomocí **k-means **algoritmu
Nastavení rozptylu (): určí se, jak „široká” má být Gaussova funkce
- počítá se z průměrné vzdálenosti bodů ve shluku od jeho středu ():
Trénování výstupních vah (): lineární regrese
- výstupní vrstva je lineární, takže LR stačí
- daleko rychlejší než gradientní metoda
k-means
- iterativní algoritmus pro shlukování dat do skupin
- Vstup: data a cílový počet shluků
- Inicializace: náhodně zvolíme středů
- Přiřazení: každý bod je přiřazen k nejbližšímu středu
- Přepočítání: každý střed se posune do těžiště bodů, které k němu byly v předchozím kroku přiřazeny
- opakujeme dokud nejsme spokojeni (často do té doby dokud se středy nepřestanou hýbat)
RBF sítě vs MLP
| Vlastnost | Vícevrstvý perceptron (MLP) | RBF síť |
|---|---|---|
| Základní jednotka | Globální (nadrovina dělí prostor) | Lokální (aktivuje se jen v okolí středu) |
| Aktivace | Skalární součin + sigmoida/ReLU | Vzdálenost od středu + Gaussova fce |
| Trénování | Backpropagation (pomalé, hrozí lokální minima) | Hybridní (k-means + regrese – velmi rychlé) |
| Geometrie | “Rozřezává” prostor přímkami | “Pokrývá” prostor “bublinami” |
| Využití | Komplexní hierarchické rysy | Aproximace funkcí, lokální vzory |
Kdy použít RBF
- potřebuju rychlé trénování
- na aproximaci funkcí
- málo-dimenzionální smooth data
- novelty-detection – RBF umí pracovat i s daty které nikdy nevidělo
Kdy použít MLP
- vysoce dimenzionální data
- generalizace známých trendů
- deep learning
Konvoluční sítě
- klasifikace obrázků
- problém: obrázky jsou hrozně velké – typicky máme více než pixelů a každý má 3 barevné kanály
- na vstupu máme 30 000 hodnot, což je pro plně propojené sítě strašně moc
- konvolučky (CNN) to řeší sdílením vah
Architektura CNN
- první vrstvy detekují jednoduchá hrany a čáry
- hlubší vrstvy získávají díky konvoluci kontext a detekují složitější objekty jako oči, kola, či obličeje
Konvoluce
Konvoluční jádro – malá matice vah (např. nebo ), kterou projedeme obrázek
v každé pozici se provede skalární součin filtru a pod-výřezu obrázku, výsledek se zapíše do mapy příznaků (feature map)
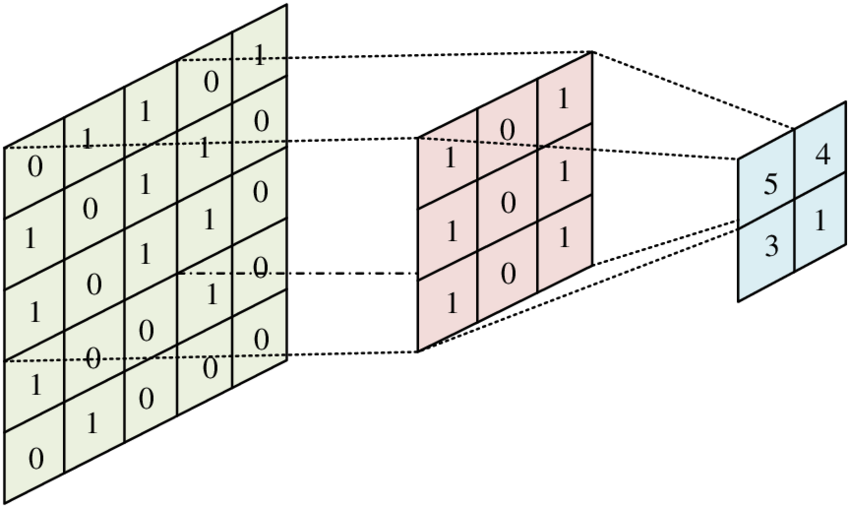
- zelená – původní obrázek; červená – filtr; modrá – feature map
- stride – délka kroku okénka
Jeden filtr používá stejné váhy pro celý obrázek (sdílení vah)
- drastické snížení počtu parametrů
Pooling (sub-sampling)
například max-pooling – z oblasti feature mapy vybere nejvyšší hodnotu
opět snižujeme velikost obrázku
zajišťuje že je síť odolná vůči malým posunům objektu
Plně propojené (dense) vrstvy
- zbylá data se „zploští” a proženou klasickou plně-propojenou sítí, která rozhodně o výsledné třídě
Matoucí vzory (Adversarial patterns)
obrázky upravené tak, že člověk změnu nevidí, ale síť vrátí úplně jiný výsledek
Příčina: vysoká linearita sítí – malé změny se napříč vrstvami nasčítají, až „přetlačí” správnou klasifikaci
FGSM (Fast Gradient Sign Method): technika, která využívá gradient chybové funkce k vytvoření šumu
k obrázku pak šum přičteme:
i malé dokáže síť spolehlivě zmást, ale člověk si ničeho nevšimne
Rizika: např. pokud chytře nalepíme nálepky na dopravní značky, tak ji samořídící auto nerozezná (nebo klasifikuje špatně) a může dojít k nehodě
Pokročilé techniky
Style transfer
- přenos uměleckého stylu
- využívá faktu, že vnitřní vrstvy CNN „vidí” svět jinak
- Aktivace vnitřních vrstev = Obsah – co na obrázku doopravdy je
- Korelace mezi aktivacemi = Styl – tahy štětcem, barvy, textury
- optimalizujeme obrázek tak, aby jeho aktivace odpovídaly skutečnému obsahu a jeho korelace odpovídaly stylu malby
Generative Adversarial Networks (GAN)
- hra dvou sítí „kočka a myš”:
- Generátor: vytváří falešné obrázky, snaží se oklamat druhou síť
- Diskriminátor: učí se poznat rozdíl mezi pravým obrázkem z trénovací množiny a podvrhem od generátoru
- obě sítě se navzájem učí a zlepšují, až generátor tvoří realistické obrázky
Rekurentní neuronové sítě
- narozdíl od feed-forward sítí povolujeme cykly
- informace z předchozích kroků výpočtu ovlivňuje aktuální výpočet
- vnitřní stav: neuron dostává na vstup nejen aktuální data , ale i svou vlastní aktivaci z předchozího kroku
- použítí: když záleží na kontextu a historii
- předpovídání počasí, akciového trhu, …
- zpracování přirozeného jazyka – strojový překlad, generování textu
- rozpoznávání řeči
Trénování a problém gradientu
- Bakpropagation Through Time (BPTT)
- abychom mohli RNN trénovat, musíme síť „rozvinout v čase” (unroll)
- představíme si ji jako velmi hlubokou dopřednou síť
- každá vrstva odpovídá jednomu časovému koku
- poté aplikujeme klasický backpropagation
- abychom mohli RNN trénovat, musíme síť „rozvinout v čase” (unroll)
- Problém: při BPTT se gradient šíří zpět přes mnoho časových kroků, kde jej mnohokrát násobíme stejnou maticí rekurentních vah
- Mizející gradient – malé váhy ()
- po několika krocích gradient úplně zanikne
- síť se nenaučí dlouhodobé závislosti
- Explodující gradient – velké váhy ()
- gradient hrozně moc roste a výpočet je nestabilní
- Mizející gradient – malé váhy ()
Exho State Networks (ESN)
- reservoir computing
- řeší problém gradientu RNN tak, že rekurentní části sítě netrénují
- Architektura: velká vrstva náhodně propojených neuronů (rezervoár)
- Princip: vstupy jsou náhodně transformovány do vysoce-rozměrného vnitřního stavu
- Trénování: váhy uvnitř rezervoáru jsou fixní a náhodné, trénuje se pouze výstupní vrstva za pomocí lineární regrese
- Výhody: extrémně rychlé trénování, absence problémů s gradientem
LSTM (Long Short-Term Memory)
- řeší problém gradientu pomocí speciální architekruty neuronu – LSTM buňky
Architektura buňky
Vstup buňky:
- její stav z předcházejícího kroku
- spojení jejích výstupů v předcházejícím stavu a nových vstupů
Brány:
- Forget gate () – co ze staré paměti vymazat
- Input gate – které nové informace uložit
- Output gate () – co z aktuální paměti poslat na výstup
Výpočet:
na základě vstupů spočítáme a :
- jsou váhy a biasy a je sigmoida
- sigmoida se používá protože její range je
- 0 = nic nepustim, 1 = pustim všechno
- jsou váhy a biasy a je sigmoida
z těch samých hodnot spočítáme kandidáta na nový vnitřní stav:
- jsou váhy a biasy pro výpočet stavu
- tanh používáme I guess zase pro jeho range
- chceme vědět na jakou stranu provést úpravu
- jsou váhy a biasy pro výpočet stavu
spočítáme nový stav buňky:
- kde značí násobení po složkách
spočítáme výstup buňky z aktuálního stavu a output brány:
- jsou váhy a biasy pro výstupní bránu
hlavní výhoda: buňka má zafixovanou rekurentní váhu na 1
- informace jí jen protéká a brány ji jen jemně upravují
- LSTM si dokáže pamatovat souvislosti i přes stovky časových kroků bez problému s gradientem
Srovnání
| Typ sítě | Trénování | Hlavní výhoda | Hlavní nevýhoda |
|---|---|---|---|
| Základní RNN | BPTT (všechny váhy) | Jednoduchost | Mizející gradient (krátká paměť) |
| ESN | Jen výstup (Regrese) | Extrémní rychlost, stabilita | Potřeba velkého náhodného rezervoáru |
| LSTM | BPTT (všechny váhy) | Dlouhodobá paměť, state-of-the-art | Výpočetně náročnější (mnoho vah) |
Neuroevoluce
- evoluce neuronových sítí
Evoluce vah
- fixní topologie sítě
- jedinec – vektor reálných čísel (vah)
- genetické operátory – standardní evoluční strategie
- přičtení šumu z normálního rozdělení apod.
- výhody:
- paralelizace – vyhodnocování jedinců je nezávislé, snadno se škáluje
- sparse rewards – gradientní metody selhávají, pokud dostaneme odměnu až na konci
NEAT
NeuroEvolution of Augmenting Topologies
vyvíjí jak váhy, tak topologii
- běžně začíná od nejjednodušší struktury, postupně ji zesložiťuje
jedinec – seznam genů pro uzly a genů pro spoje
- každý spoj obsahuje: odkud, kam, váha, aktivní/neaktivní, inovační číslo
mutace:
- přidání spoje – nová hrana mezi existujícími uzly
- přidání uzlu – existující hrana je podrozdělena (původní hrana se deaktivuje)
křížení:
jedinci se zarovnají podle inovačních čísel
společné geny se dědí náhodně, unikátní geny se dědí pouze od zdratnějšího jedince
speciace – algoritmus dělí populaci do druhů podle topologické podobnosti
- jedinci v rámci druhu sdílí fitness (často je to fitness toho nejlepšího jedince)
- chráníme tím mladé strukturální inovace
- jedinci v rámci druhu sdílí fitness (často je to fitness toho nejlepšího jedince)
Význam inovačních čísel
- globální identifikátory změn
- každá nová strukturální změna (nový spoj/uzel) v celé populaci dostane unikátní číslo
- řeší problém Competing Conventions – jak poznat, že dva různé řetězce genů dělají v síti to samé
HyperNEAT a coDeepNEAT
- HyperNEAT – váhy výsledné sítě nejsou přímo v genotypu, ale jsou počítány jinou sítí (tzv. CPPN)
- CPPN síť dostává jako vstup souřadnice neuronů a vrací váhu spoje mezi nimi
- umožňuje vytvářet sítě s geometrickou pravidelností
- např. když vyvíjíme síť pro ovládání robotického pavouka s 8 nohama, CPPN síť se naučí, že všechny neurony co jsou geometricky po obvodu (tedy nohy) se mají chovat stejně
- obecně je to zjednodušení vývoje pro úlohy, které mají nějakou geometrickou pravidelnost
- coDeepNEAT – rozšíření pro moderní deep learning
- populace je rozdělena na moduly a plány (blueprints), které říkají, jak moduly poskládat dohromady
- koevoluce – vyvíjí odděleně celé moduly (bloky vrstev)
- příklad: pokud bychom chtěli udělat jednu velkou neuronku pro armádu, pak si natrénujeme modul pro lukostřelce, pěšáky, katapulty, a pak blueprint pro to, jak by měla armáda fungovat jako celek
Novelty Search
místo abychom hledali nejlepší řešení na základě fitness, hledáme nejnovější řešení
- odměňujeme jedince za to, že se chovají jinak než všichni ostatní v historii
výhody a motivace:
- obrana proti padání do lokálních optim
- když je těžké najít nějakou dobrou fitness funkci
Hluboké zpětnovazební učení
Value-based
- metody snažící se odhadovat -hodnoty pro nalezení nejlepší strategie
Q-učení vs Hluboké Q-učení
- Q-učení – hodnoty jsou uloženy v obří tabulce
- funguje dobře jen pro malé stavové prostory
- Hluboké Q-učení (DQN) – tabulku nahrazuje neuronová síť
- vstup sítě: stav
- výstup sítě: odhadované hodnoty pro všechny možné akce
- síť se učí zobecňovat – i když neviděla přesně tento stav, dokáže odhadnout dobrou akci na základě podobných situací
Trénování sítě pro hluboké Q-učení
podle Bellmanovy rovnice pro
porovnáváme aktuální hodnotu od prostředí s hodnotou spočítanou pomocí Bellmanových rovnic z
minimalizujeme mean square error rozdílu mezi a (Teporal Difference Error)
- stejně jako ve standardním Q-učení uvažujeme, že v dalším stavu vybereme nejlepší akci podle aktuálního odhadu
chybová funkce je:
- jsou parametry neuronové sítě reprezentující matici
pro výpočet chybové funkce tak potřebujeme znát stav , vybranou akci , odměnu a následující stav
- všechno to získáme, pokud necháme agenta provádět akce v prostředí
- problém: tímto bychom měnili přímo funkci odhadující
- měníme chování agenta i odhady zároveň
- problém se stabilitou
Stabilizační triky
Experience Replay
- místo abychom se učili z akce hned, uložíme si čtveřici do paměti
- při trénování z paměti vybíráme náhodné vzorky
- rozbíjení korelací – po sobě jdoucí stavy v jedné hře jsou si velmi podobné
- náš náhodný výběr zajistí, že se síť učí z pestré směsi situací
Target Network
oddělíme síť pro výběr akce a síť pro odhad hodnoty
- Trénovaná síť () – aktualizuje se v každém kroku
- Cílová síť () – používá se pro výpočet „správného” odhadu v Bellmanově rovnici
- její váhy se aktualizují jen jednou za čas
chybová funkce se pak změní takto:
- u výběru nejlepší akce používáme cílovou síť s
zabránění oscilacím – bez níc by se při každé úpravě vah změnil i cíl, ke kterému síť směřuje
Policy-based
- kašlem na odhadování , jdem rovnou hledat policy
Policy Gradient metody
např. REINFORCE
místo odhadování můžeme přímo optimalizovat strategii (policy) s parametry
cílem je maximalizovat celkovou očekávanou odměnu:
k úpravě vah používáme gradient celkové odměny:
- : pravděpodobnost výběru akce ve stavu
- : kumulovaná diskontovaná odměna od času do (konce epizody)
- logaritmus se tam objevuje díky matematickému triku při derivování střední hodnoty ()
při velkých odměnách můžeme dostávat velké rozptyly hodnot gradientu
- se často nahrazuje jinými výrazy
- třeba rovnou , která se pak učí podobně jako hodnoty v DQN
- advantage
- se často nahrazuje jinými výrazy
Actor-Critic
- kombinace value-based a policy-based metod
- Actor (policy) – učí se chovat v prostředí
- Critic (value) – učí se na základě prostředí odměňovat aktéra
Advantage
místo toho aby síť počítala jen čistou odměnu , počítáme tzv. advantage
- o kolik je konkrétní akce lepší než průměrná akce v daném stavu
ze vztahů mezi a lze odvodit alternativní vzorec:
- tenhle vzorec přímo odpovídá implementaci Advantage Actor-Critic:
- Actor: pravděpodobnostní strategie
- realita dle actora:
- Critic: odhad hodnoty
- predikce kritika:
- Actor: pravděpodobnostní strategie
- tenhle vzorec přímo odpovídá implementaci Advantage Actor-Critic:
advantage výrazně snižuje rozptyl při učení
- pokud jsou všechny odměny v prostředí obrovské, gradienty by byly nestabilní
- advantage vycentruje hodnoty kolem nuly
Pokročilé architektury
DDPG (Deep Deterministic Policy Gradient)
DQN neumí pracovat se spojitými akcemi, protože nedovede spočítat přes nekonečno možností
- místo toho DDPG zavede novou neuronku, která bude vracet konkrétní akce
Actor-critic architektura:
Actor: – síť vracející konkrétní akci
- deterministická: nebude prohledávat prostor sama o sobě
- často se během tréninku přidává nějaký noise
- deterministická: nebude prohledávat prostor sama o sobě
Critic: – funkce počítající
DDPG používá oba stabilizační triky, označme pomocí a parametry cílových sítí pro a
aktualizace parametrů sítě pro :
- oproti minulému vzorci již nehledáme přes všechna , ale dostáváme výstup z
trénování sítě :
- chceme aby vracela akce, které maximalizují ve stavu
- maximalizujeme pomocí gradientní metody výraz:
A3C (Asynchronous Advantage Actor-Critic)
- místo jedné paměti (Experience Replay) spustíme mnoho agentů paralelně v různých kopiích prostředí
- každý agent zažívá něco jiného, což přirozeně rozbíjí korelace dat
- aktualizace od všech agentů se posílají jedné hlavní síti
PPO (Proximal Policy Optimization)
- aktuální industry standard
- klasický policy gradient krok může být moc velký – cliff problem
- PPO to řeší „uřezáváním” objektivů – nová policy pak není tak daleko od té staré po jednom kroku
Shrnutí
| Algoritmus | Typ | Prostor akcí | Klíčový rozdíl |
|---|---|---|---|
| DQN | Value-based | Diskrétní | Replay Buffer + Target Network |
| REINFORCE | Policy | Obojí | Monte Carlo (vysoká variance) |
| A3C/A2C | Actor-Critic | Obojí | Advantage + Parallelismus |
| DDPG | Actor-Critic | Spojitý | Deterministic Policy pro spojité prostory |
| PPO | Policy-based | Obojí | Užezává updaty pro zachování stability |
Particle Swarm Optimization
- inspirace fyzikálním pohybem a sociálními interakcemi
- skupina ptáků hledá místo s největším množstvím potravy
- každý jedinec letí svým vlastním směrem, ale po očku sleduje, kde už někdo něco našel
Aktualizace rychlosti a polohy
každá částice je definována svou polohou a rychlostí
v každém kroku se tyto hodnoty aktualizují dle následujících rovnic:
- , – pozice v prostoru, kde měl daný jedinec nejlepší fitness a kde byla nejlepší fitness napříč celou populací
- , – náhodná čísla mezi 0 a 1
- – setrvačnost
- , – jak moc je jedinec přitahován ke svému a ke globálnímu nejlepšímu řešení
Topologie v PSO
- topologie určuje, jakým způsobem se mezi částicemi šíří informace
- výběr topologie zásadně ovlivňuje exploration/exploitation ratio
Globální topologie – úplný graf
- všichni jedinci se ihned dozvídají info o
- vysoký exploitation – velmi rychlá konvergence k řešení za cenu rizika uvíznutí v lokálním optimu
Lokální topologie
- částice komunikují jen s omezenou skupinou sousedů
- více explorace – pomalejší konvergence, ale je odolnější vůči padání do lokálních optim
- Geometrická – sousedé jsou určeni fyzickou vzdáleností v prostoru
- pokud jsou k sobě částice dostatečně blízko, nasdílejí si info
- Sociální – sousedství je fixně definováno předem (např. grafem)
- často kruhová topologie – každá částice sleduje jen dva dané sousedy bez ohledu na to, jak daleko se pak od sebe v praxi nacházejí
Použití ve spojité optimalizaci
přímo navrženo pro spojitou optimalizaci (hledání extrémů funkcí s reálnými čísly)
Přímá reprezentace – částice přímo odpovídá vstupním parametrům optimalizované funkce
Fitness funkce – fitness částice je přímo hodnota optimalizované funkce v daném bodě
narozdíl od jiných metod (gradient descent, newton method) PSO nepotřebuje znát derivaci funkce
- ideální pro složité, nespojité, a nehladké funkce
Ant Colony Optimization
- inspirace mravenčími hejny
- kombinace lokálního rozhodování mravenců s globální pamětí ve formě feromonů
- používá se na grafové problémy
Základní pojmy
algoritmus používá dvě hlavní proměnné, které ovlivňují rozhodování mravence při výběru cesty z vrcholu do vrcholu
Feromon () – nepřímá paměť kolonie
- hodnota měnící se v čase (mravenci pokládají feromon, který se postupně vypařuje)
- čím více feromonu na hraně je, tím je pro mravence lákavější
Atraktivita () – viditelnost, heuristická informace
- neměnná vlastnost hrany v grafu
Generování řešení
mravenec se pohybuje po grafu a v každém vrcholu se rozhoduje, kam dál na základě nějaké pravděpodobnosti
pravděpodobnost, že mravenec přejde z do je úměrná součinu feromonu a atraktivity:
- – síla feromonu
- – síla atraktivity
obvykle si mravenci udržují seznam navštívených vrcholů, aby se nevraceli do míst, kde už byli (šikovné pro TSP)
Aktualizace feromonu
- učení kolonie ve dvou krocích:
- Vypařování – množství feromonu na všech hranách se sníží o určitý koeficient
- dovoluje kolonii zapomenout stará, horší řešení
- obrana proti uvíznutí v lokálním optimu
- Pokládání – na hrany, které byly součástí nalezených cest, se přidá nový feromon
- množství feromonu závisí na kvalitě řešení ():
celkový update pak vypadá následovně:
- – dobře zvolená konstanta (jak moc váhy dáváme do pokládání feromonu)
- – (invertovaná) kvalita řešení nalezeného mravencem
- jelikož dělíme , pak obviously s větší hodnotou má mravenec menší sílu feromonu
Použítí ACO na konkrétní problémy
Travelling Salesman Problem (TSP)
- Graf: vrcholy jsou města, hrany jsou silnice
- Cíl: navštívit všechna města a vrátit se zpět s minimální délkou cesty
- ACO přístup:
- – délka cesty
- – převrácená hodnota délky hrany
Vehicle Routing Problem (VRP)
- složitější verze TSP – máme sklad, flotilu aut a zákazníky čekající na různé velké dodávky naší komodity
- Omezení: kolik komodity se do auta vejde a jakou vzdálenost najednou ujede
- Cíl: minimalizovat počet aut a celkovou ujetou vzdálenost
- ACO přístup:
- mravenec vybírá dalšího záklazníka dle stejného pravděpodobnostního pravidla jako TSP
- pokud by návštěva dalšího záklazníka překročila kapacitu auta, mravenec se musí vrátit do skladu, naložit zpět náklad a vyrazit znovu
Artificial Life
- studuje život jaký by mohl být v jiných médiích
- z úplně jednoduchých pravidel vzniká nečekaně složité a inteligentní chování
Typy umělého života
- dělí se na typy podle toho, z čeho jsou organismy stvořeny
- Soft – život existující pouze v počítačových simulacích
- programy, digitální algoritmy
- modelování interakcí a evoluce
- Hard – fyzické stroje a roboti
- vytváření umělých entit, které se pohybují a reagují v reálném světě
- Wet – laboratorní výzkum biochemických procesů
- tvoření umělé DNA nebo syntetické buňky „ve zkumavce”
Silný vs. Slabý život
- různé filosofické pohledy na to, co jsme vytvořili
- Silný – život je proces nezávislý na médiu
- pokud počítačový program vykazuje všechny známky života (rozmnožování, metabolismus, evoluci, …), pak je to život
- Slabý – simulace života není život
- počítačové modely jsou jen nástrojem pro studium skutečné biologie
Celulární automaty (CA)
- mřížky, kde každá buňka mění barvu/stav podle barev svých sousedů
- 1D automaty – jednoduchá řada buněk
- nový stav buňky závisí na ní a jejích sousedech vlevo/vpravo
- 2D automaty – plošná mřížka
- stav závisí na okolí
- game of life
Conwayova Game of Life
- v každém kroku se buňka změní podle počtu živých sousedů
- Osamění/Přemnožení – živá buňky s < 2 nebo > 3 živými sousedy umírá
- Přežití – živá buňka s 2 nebo 3 sousedy žije dál
- Zrození – mrtvá buňka s právě 3 sousedy ožívá
- CGoL je Turingovsky úplný systém
- yo WHAT THE FUCK
Langtonův mravenec
jednoduchý agent na mřížce se dvěma barvami (černá/bílá)
chování mravence dle barvy políčka, kde se nachází:
- bílá: změň barvu políčka na černou, otoč se o 90° doprava a udělej krok vpřed
- černá: změň barvu políčka na bílou, otoč se o 90° doleva a udělej krok vpřed
Dálnice – po počátečním chaosu mravenec téměř vždy upadne do cyklu 104 kroků, který vytváří pravidelný pruh a marvenec po něm nekonečně utíká jedním směrem
Systém Tierra
- simulace digitálního ekosystému v paměti počítače
- Jedinci: kusy spustitelného kódu
- v Tieře je to speciální instrukční sada o 32 instrukcích
- cílem jedince je přežít a zkopírovat se do volné paměti
- Adresování – komplementární páry
- místo číselných adres
- pokud chce program skočit na určitou funkci, vloží za instrukci skoku sekvenci instrukcí
NOP0aNOP1- procesor pak v paměti hledá nejbližší místo v paměti s opačnou sekvencí (prohozené
NOP0zaNOP1)
- procesor pak v paměti hledá nejbližší místo v paměti s opačnou sekvencí (prohozené
- simulace párování bází v DNA
- umožňuje evoluci – kód se může v paměti posouvat
- všichni jedinci v systému běží paralelně
- každý má přiřazen virtuální procesor
- jedinci nemohou přepisovat instrukce jiného jedince, ale mohou je číst a vykonávat
- na začátku simulace se začíná s jedním jedincem, který umí sám sebe zkopírovat
- při replikaci je malá šance, že dojde k mutaci bitu v jedinci
Evoluce v Tierře (paraziti)
díky mutacím vznikají zajímavé formy „života”
Paraziti – programy, které ztratily vlastní kód pro kopírování
- přežívají jen tak, že najdou v paměti sousedního jedince a „vypůjčí” si jeho kopírovací proceduru
- jsou tak menší a tím pádem rychlejší v reprodukci
Hyper-paraziti – paraziti na parazitech
odhalí parazita v paměti a změnou registru jej donutí (ošálí), aby místo sebe kopíroval právě hyper-parazita
takovej bakteriofág
Creatures
- počítačová hra
- hráč má za úkol starat se o tzv. Norny
- Nornové mají neuronovou síť jako mozek
- hráč je musí učit, pomáhat prozkoumávat prostředí a bránit se před jinými druhy
Simulace složitých systémů
- možná aplikace umělého života je simulace složitých (nejen) biologických systémů
- Moranův proces – moje bakalářka :3
- dva základní typy smulací:
- black-box – imitace chování bez ohledu na to, jestli vnitřní struktura nějak souvisí s reálnou vnitřní strukturou
- white-box – simulace je založená na principech, které byly pozorovány v reálném světě
- založeny na přesném pochopení studovaného systému